网易KM社区分享-小P老师服务GC卡顿定位解决
小P老师作为有道AI大模型的重点服务,稳定性与低延迟至关重要。但随着开学季到来,接口流量增加,服务偶现请求延迟升高和GC卡顿异常重启现象。
本文总结上述问题的排查思路及定位过程,相信对遇到内存泄漏、CPU升高、JVM GC异常等问题的小伙伴,有借鉴意义。
一、背景和现象
小P老师服务(java服务容器部署、jdk17、G1回收器)核心任务是提供教育场景下的大模型对话式问答。随着开学季到来,流量也逐渐上升,保障服务稳定性是比较重要的任务之一。
大模型对话式问答通常是一个流式过程,模型回答是一段一段输出给用户的,为了观察到整个模型的延时情况,大模型回答完毕的时间(total time)以及大模型每一段回答的时间(interval time)都添加了监控。
近期发现,小P老师服务里子曰大模型interval time的监控总是超时告警,但是子曰大模型自身的interval time监控确实正常的,同时很奇怪的是只有一个或者部分容器pod出问题。
这两个监控有什么区别呢?简单来说一个是A使用B时对B的监控,另外一个是B对自身的监控,所以理论来说他两监控应该基本一致才是符合预期的(抛去网络延时)。
从这一现象看,说明小P老师本身代码逻辑存在耗时情况或者网络有问题。
另外之前小P也出现过类似情况,我们使用了Huggingface去做大模型token计算,这个组件cpu占用率很多,所以按照之前惯例会查看cpu是否够用。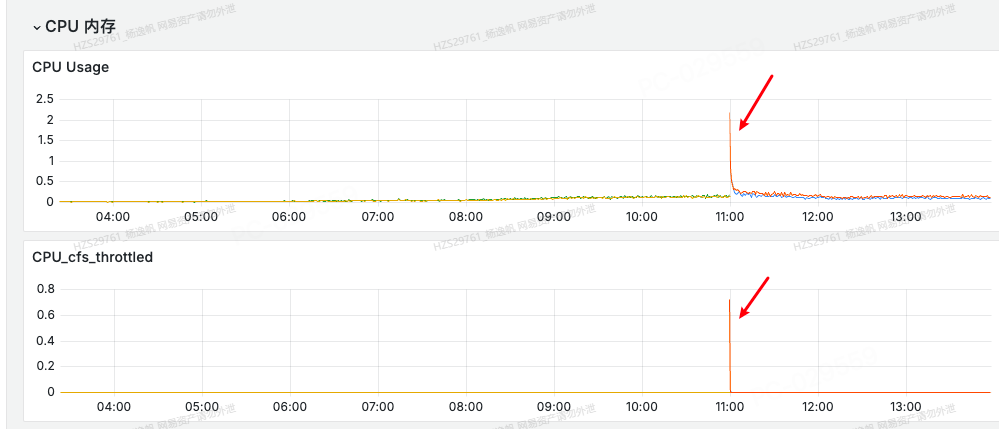
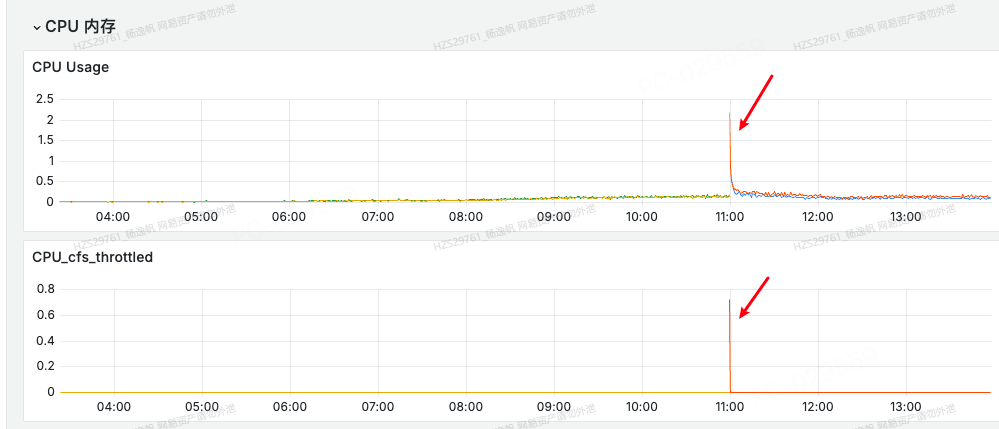
图1 容器cpu使用图
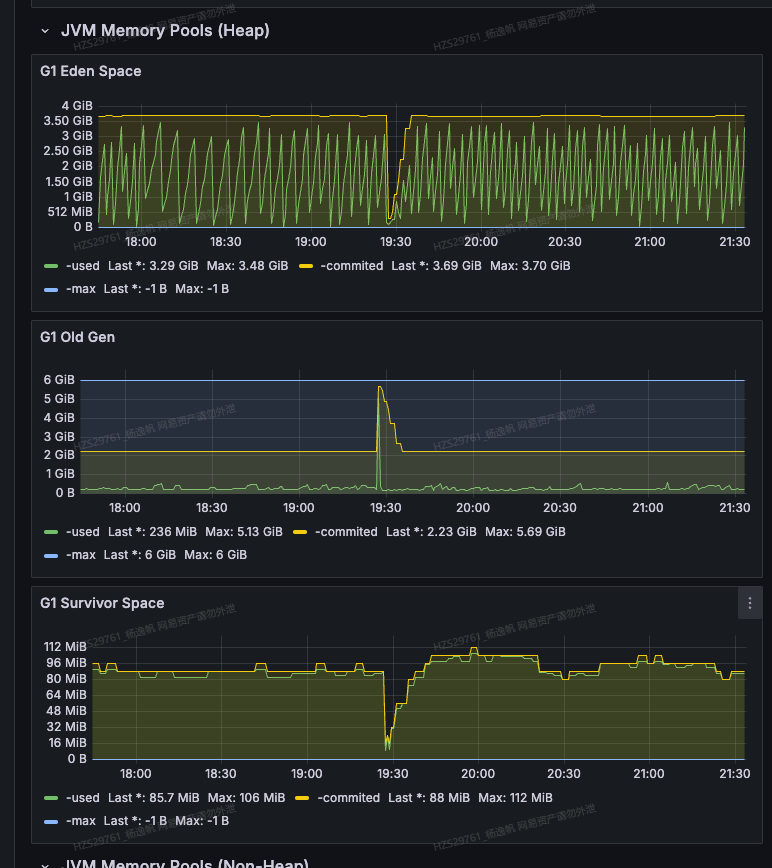
图2 jvm监控图
于是发现了图1这样的现象,在容器cpu监控图中发现在服务告警期间cpu usages(使用量)和cpu cfs throttled(抢占)有尖刺。同时也是机缘巧合,想看看jvm里cpu使用占用率多少,于是在图2(黄色线是分配的内存、绿色线是使用的内存)发现了比较重要的一个信息,jvm在这期间eden区分配降低,old区使用、分配激增,维持了一段时间后就自行恢复了。于是我便去查看了一段时间内的GC日志
1 | [2024-10-23T20:23:56.727+0800] GC(77) Pause Young (Normal) (G1 Evacuation Pause) |
确实发现了异常的点,标记1可以看出Humongous regions数量非常多且这一次GC并没有回收该区域的内容。(Normal GC是会回收Humongous区域的)
标记2可以看出整个GC耗时大概5.4s,当然从标记3可以更清楚的看出GC耗时,所以我们猜测子曰大模型interval time告警可能和GC耗时过久有关系。
至此我们整合一下问题现象:
- 小P老师服务对子曰大模型的延时监控发生告警,且与子曰大模型自身监控不一致
- 只有一部分pod有问题
- 告警期间服务cpu使用率激增
- 告警期间jvm内存eden区域分配减少,old区域使用、分配激增,一段时间后恢复
Humongous regions回收不明显,GC停顿过长
根据上述现象,我们可以判断出服务延时告警时和GC有关系,也就是需要从内存的角度来分析为什么GC会停顿这么久,可以算是一个切入点。
分析内存有一个得力工具MemeoryAnayzer(MAT),接下来会先重点介绍一下这个工具,同时也会介绍在jdk17中的G1垃圾回收器。当然如果对此熟悉的可以直接跳过看定位过程。
二、Garbage-First (G1) 垃圾回收器
Garbage-First (G1) 垃圾收集器针主要对大内存多核的服务,目的是实现应用程序和环境在延迟和吞吐量之间的最佳平衡。
特点:
- 服务堆大小大于10GB。
- 对象分配和对象移动的速度可能会随着时间的推移而发生很大变化。
Rates of object allocation and promotion that can vary significantly over time.
- 堆中存在大量碎片。
- 可预测的暂停时间目标不超过几百毫秒,避免长时间的垃圾收集暂停。
2.1 基本概念
G1 将堆分为年轻代(young)和老年代(gen)。空间回收工作集中在最高效的年轻代上,偶尔也会在老年代进行空间回收。
G1 首先回收最高效区域的空间(即大部分被垃圾填充的区域,因此得名)。
G1 主要通过撤离(evacuation)来回收空间:在选定的内存区域找到存活对象复制到新的内存区域,并在过程中对其进行压缩。撤离完成后,先前的空间可用来重新分配。
G1不是实时收集器。尝试尽可能在设定的暂时时间下完成回收,但对于给定的暂停,不能保证绝对满足。
2.2 堆布局
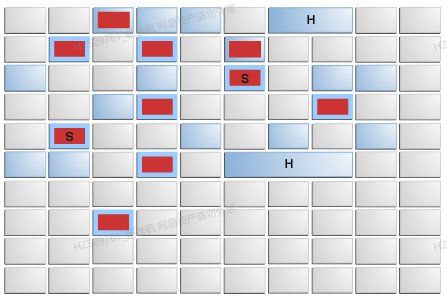
图3 G1垃圾回收器
年轻代包含eden区域(红色)和survivor区域(红色,带“S”)。这些区域内部是连续的,但在G1中这些区域通常以非连续模式排列在内存中。old区域(浅蓝色)构成老生代。对于跨多个区域的对象,会有一个非常大的old区域(浅蓝色,带“H”),叫做Humongous区域 。
应用程序总是分配到年轻代,即eden区域,巨大对象被分配到old区域。
2.3 垃圾回收周期
G1 收集器在两个阶段之间交替。young-only阶段包括垃圾回收(garbage collections),这个阶段会逐渐填满当前可用的内存
空间回收阶段是 G1 除了处理年轻代之外,还会逐步回收老生代中的空间。然后,循环从年轻代阶段重新开始。
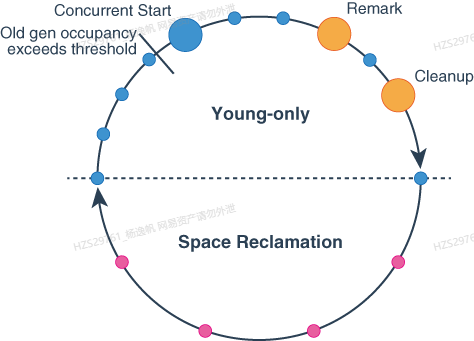
图4 垃圾回收周期预览
以下列表详细描述了 G1 垃圾收集周期的各个阶段、暂停以及阶段之间的转换:
仅年轻代阶段(Young-only phase):此阶段以Normal young collections收集开始,会将对象提升到老年代。当老年代占用率达到某个阈值时,Young-only phase和Space-reclamation phase之间的过渡就开始了。此时,G1 会执行Concurrent Start young collection,而不是Normalyoung collections。
Concurrent Start:这种类型的收集除了执行常规Normalyoung collections,还启动标记过程。并发标记确定old区域中的是否可以被回收。在收集标记尚未完全完成时,可能会发生Normalyoung collections。
Remark:此这段会完成重新标记。
Cleanup:这个阶段决定是否进行Space-reclamation phase。如果确定进行Space-reclamation phase,那么Young-only phase就会进行一次Prepare Mixed young collection.
空间回收阶段(Space-reclamation phase):此阶段会进行Mixed collections,除了young区域外,还会撤离old区域中的存活对象。当 G1 确定撤离更多老生代区域不会产生足够的可用空间时,空间回收阶段结束。
- Young-only phase: This phase starts with a few Normal young collections that promote objects into the old generation. The transition between the young-only phase and the space-reclamation phase starts when the old generation occupancy reaches a certain threshold, the Initiating Heap Occupancy threshold. At this time, G1 schedules a Concurrent Start young collection instead of a Normal young collection.
- Concurrent Start : This type of collection starts the marking process in addition to performing a Normal young collection. Concurrent marking determines all currently reachable (live) objects in the old generation regions to be kept for the following space-reclamation phase. While collection marking hasn’t completely finished, Normal young collections may occur. Marking finishes with two special stop-the-world pauses: Remark and Cleanup.
- Remark: This pause finalizes the marking itself, performs global reference processing and class unloading, reclaims completely empty regions and cleans up internal data structures. Between Remark and Cleanup G1 calculates information to later be able to reclaim free space in selected old generation regions concurrently, which will be finalized in the Cleanup pause.
- Cleanup: This pause determines whether a space-reclamation phase will actually follow. If a space-reclamation phase follows, the young-only phase completes with a single Prepare Mixed young collection.
- Space-reclamation phase: This phase consists of multiple Mixed collections that in addition to young generation regions, also evacuate live objects of sets of old generation regions. The space-reclamation phase ends when G1 determines that evacuating more old generation regions wouldn’t yield enough free space worth the effort.
空间回收后,收集周期将以另一个年轻阶段重新启动。作为兜底,如果应用程序在收集活跃度信息时内存不足,G1 将像其他收集器一样执行就会执行Full
2.4 垃圾回收阶段和回收集
garbage Collection Pauses and Collection Set
G1执行垃圾收集和空间回收是在stop-the-world pauses时间内完成的,存活的对象会从堆的一个区域移动到另一个区域,并且对这些对象的引用也会调整。
对于non-humongous的移动:
- 年轻一代(eden和survivor)的对象被复制到survivor区域或old区域,取决于它们的年龄。
- 来自old的对象被复制到其他old
对于大对象来说,除非被回收不然永远不会被移动。
对于回收集(collection set):
- 在 Young-Only ,回收集仅由年轻一代的区域以及可能被回收的巨大区域组成。
- 在空间回收(Space-reclamation)阶段,回收集由年轻代中的区域、包含可能被回收的对象的巨大区域、以及来自收集集合候选区域的一些老生代区域组成。
G1 在并发周期(concurrent cycle)内准备回收集候选区域。在Remark pause,G1 选择大量闲置空间的低利用率区域。然后在 Remark 和Cleanup pause之间并发准备这些区域以供以后收集使用。Cleanup pause根据效率对准备的结果进行排序。更高效的区域是说,有更多的空间并且回收的时间更少。mixedcollections会更喜欢这些区域。
三、MemeoryAnayzer(MAT)
3.1 重要概念
3.1.1 可达性
可达
这个对象仍然有地方引用着他
不可达
这个对象没有任何对象被引用
3.1.2 Shallow 与Retained Heap的区别
Shallow 是一个对象所消耗的内存。对象每个引用需要32或64位(取决于操作系统体系结构),每个Integer需要4字节,每个Long需要8字节,等等。
Shallow heap is the memory consumed by one object. An object needs 32 or 64 bits (depending on the OS architecture) per reference, 4 bytes per Integer, 8 bytes per Long, etc. Depending on the heap dump format the size may be adjusted (e.g. aligned to 8, etc…) to model better the real consumption of the VM.
X的Retained set表示当X被GC垃圾回收后需要移除的对象列表
Retained set of X is the set of objects which would be removed by GC when X is garbage collected.
X的Retained heap是Retained set里所有对象的Shallow大小
Retained heap of X is the sum of shallow sizes of all objects in the retained set of X, i.e. memory kept alive by X.
通俗的来说,Shallow 是这个对象的大小,Retained heap是这个对象被回收之后内存释放的大小

图5 对象引用图以及Retained Set
3.1.3 Dominator Tree
MAT提供了对象图的Dominator Tree,将对象引用图转化为Dominator Tree能够轻松识别保留内存的最大块以及对象之间的依赖关系,下面是一些定义
- X dominates Y,表示在对象图中,每一个去Y的路径上都需要经过X。
- X是Y的immediate dominator ,表示X是距离Y最近的支配者
- dominator tree 是由对象图直接构建而来,能够展现一个对象的immediate dominator
图6是将对象图(左侧)构建为dominator tree (右侧)
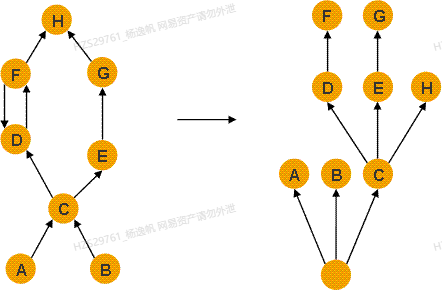
图6 对象引用图以及Retained Set
通俗的来说,X dominates Y表示,如果X被回收那么Y一定被回收。但我们常说的引用,如果X引用Y,那么Y是不一定会被回收的,因为Y有可能被Z引用。这就是为什么MAT引入 Dominator这个概念。
3.2 常用功能
3.2.1 Histogram
Histogram列举出每一个class的对象数量以及他的shallow size和retained size,可以快速找出大的对象类
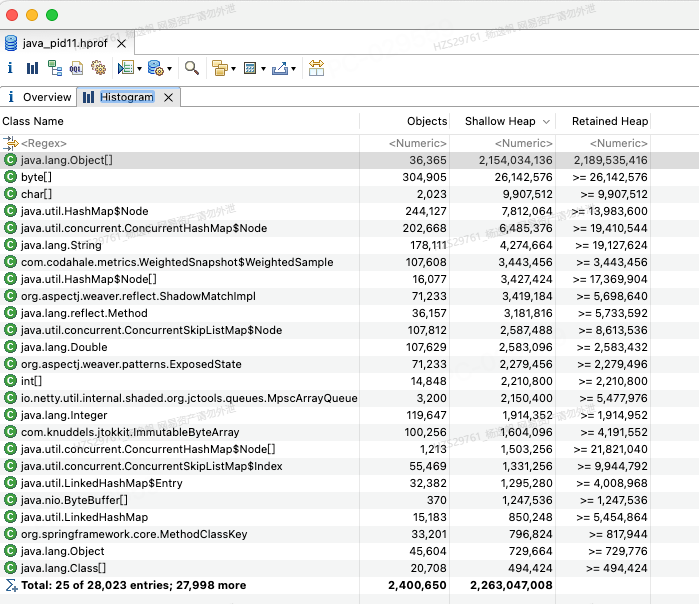
图7 Histogram列表
默认情况下retained size展示的是估算值,也可通过计算才获取他的准确值。
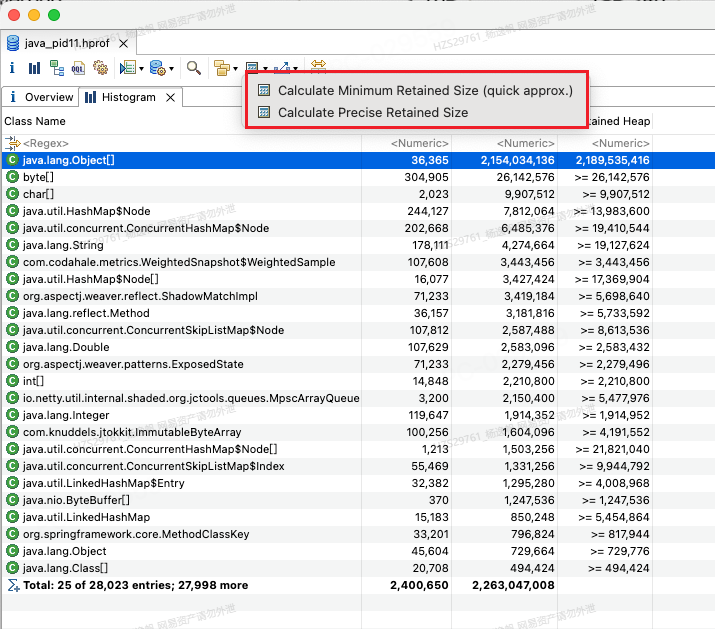
图8 Histogram计算准确retained size
可以查看对象被谁引用或者他又引用了谁
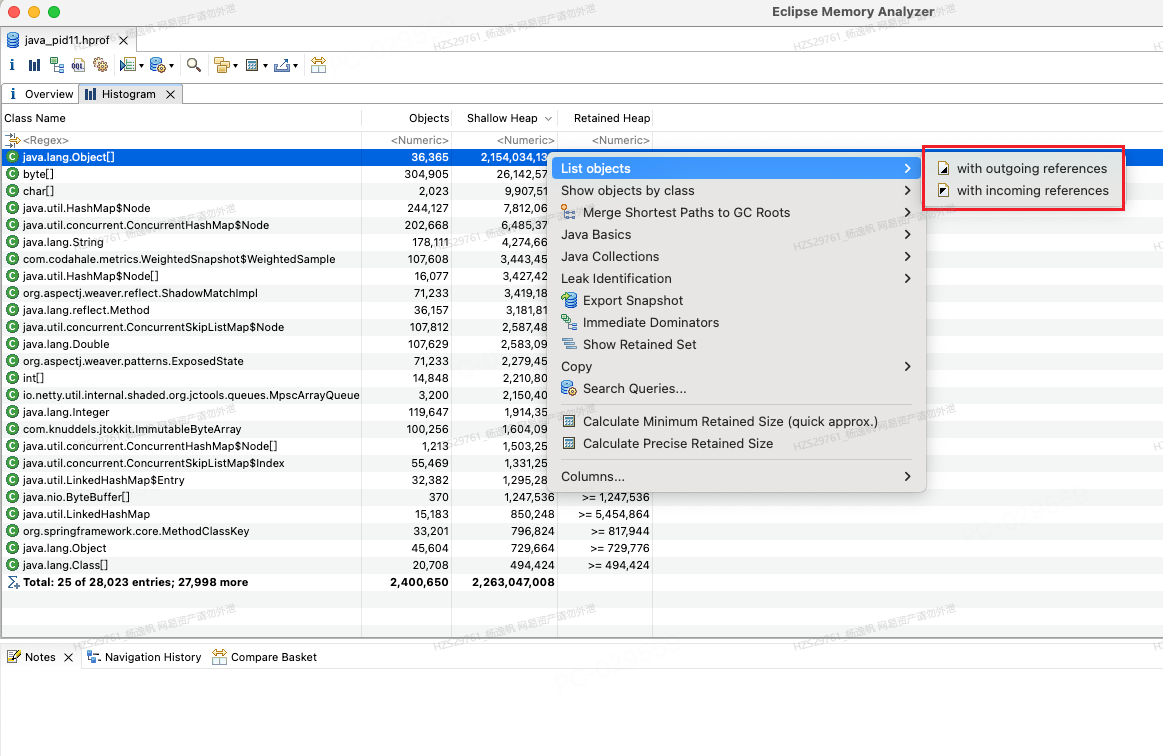
图9 Histogram查看引用关系
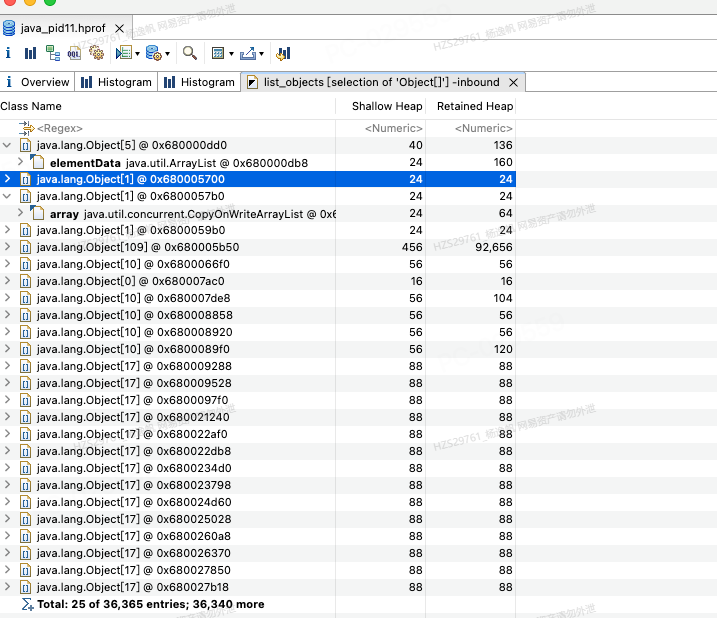
图10 Histogram查看引用关系结果
Histogram默认是通过class是分组的,也可以根据包或者加载器
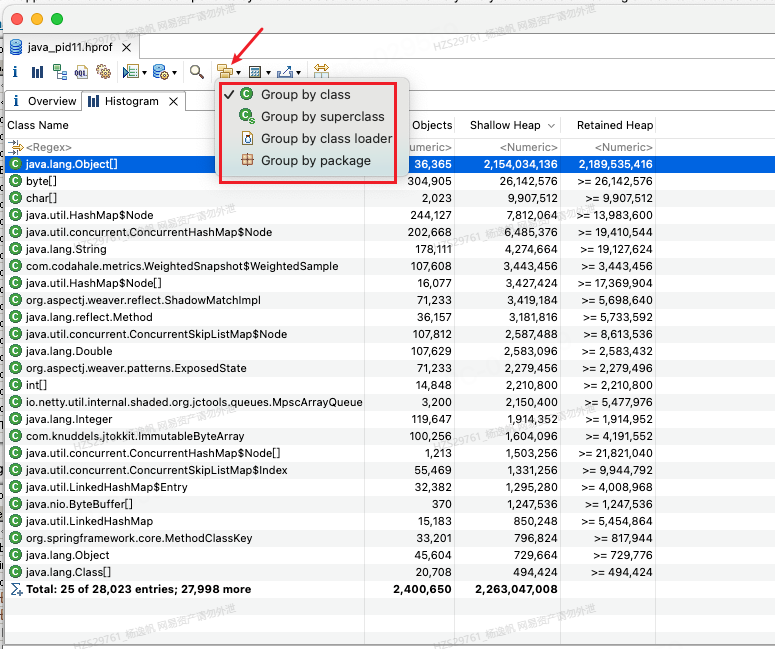
图11 Histogram通过其他类型分组
3.2.2 Dominator Tree
Dominator tree展示了在堆中最大的对象列表。X对象的下一级表示,X被回收之后需要被垃圾回收的对象列表。(也就是X直接支配的对象)同样也可以按类加载器、包进行分组。
The next level of the tree lists those objects that would be garbage collected if all incoming references to the parent node were removed.
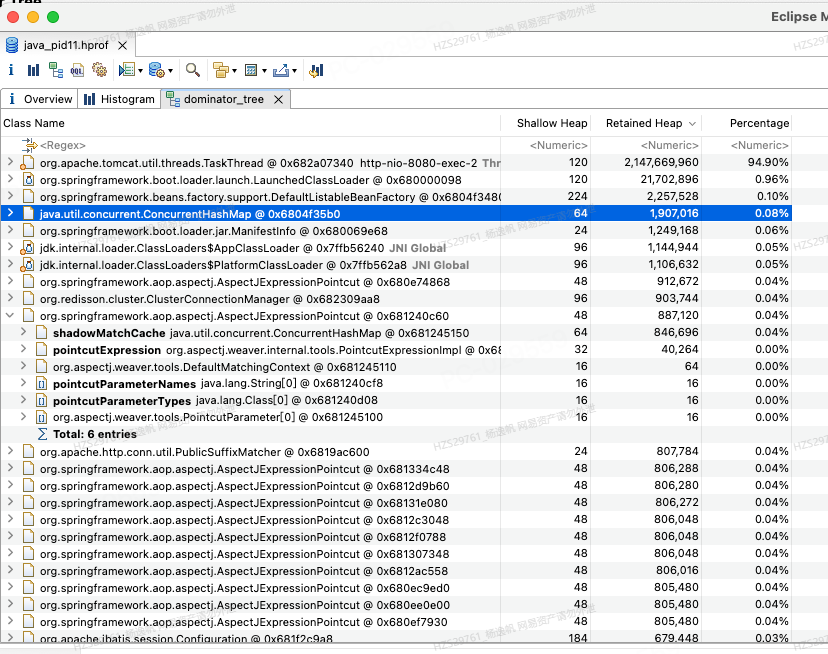
图12 Dominator Tree
以上图为例,占用堆内存最大的是TaskThread的http-no-8080-exec-2线程,其本身大小是Shallow Heap是120字节,Retained Heap是2417669960字节,占用整个堆内存94.90%。图中将AspectJExpressionPointcut展开,表示当AspectJExpressionPointcut被内存回收之后,展开列表里的所有对象都会被回收,也就是他的retained set
3.2.3 Immediate Dominators
可以快速找出当前这组(类/对象)的所有immediate dominator(直接支配者)
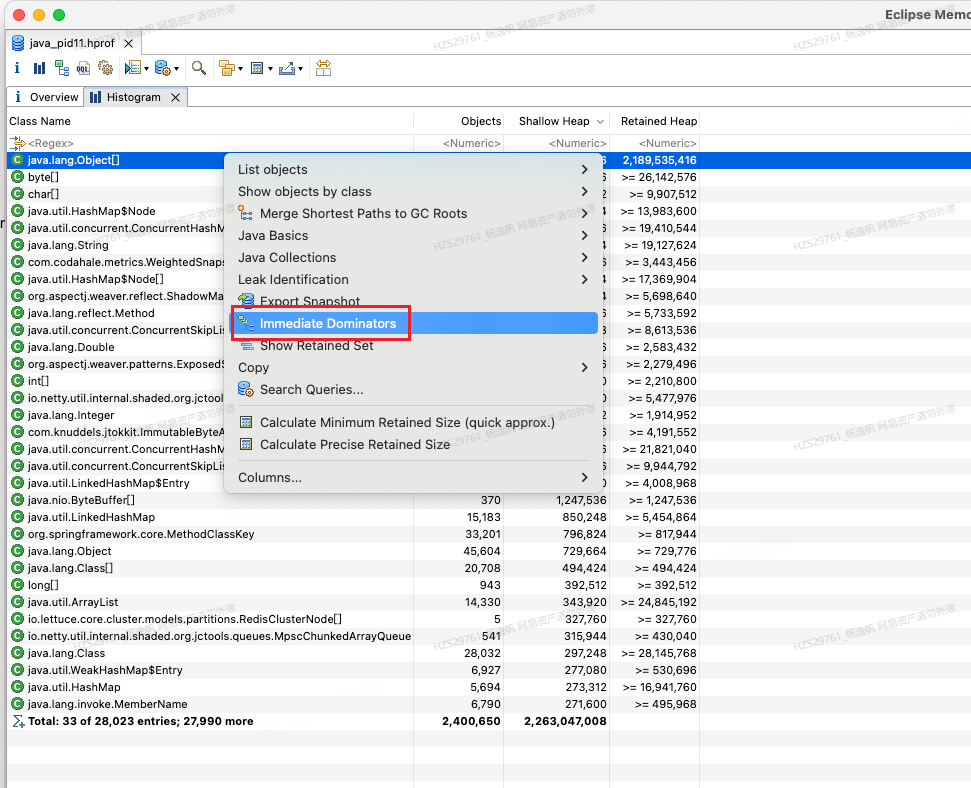
图13 Histogram找某个类的immediate dominator
下列展现支配Object[]的类列表
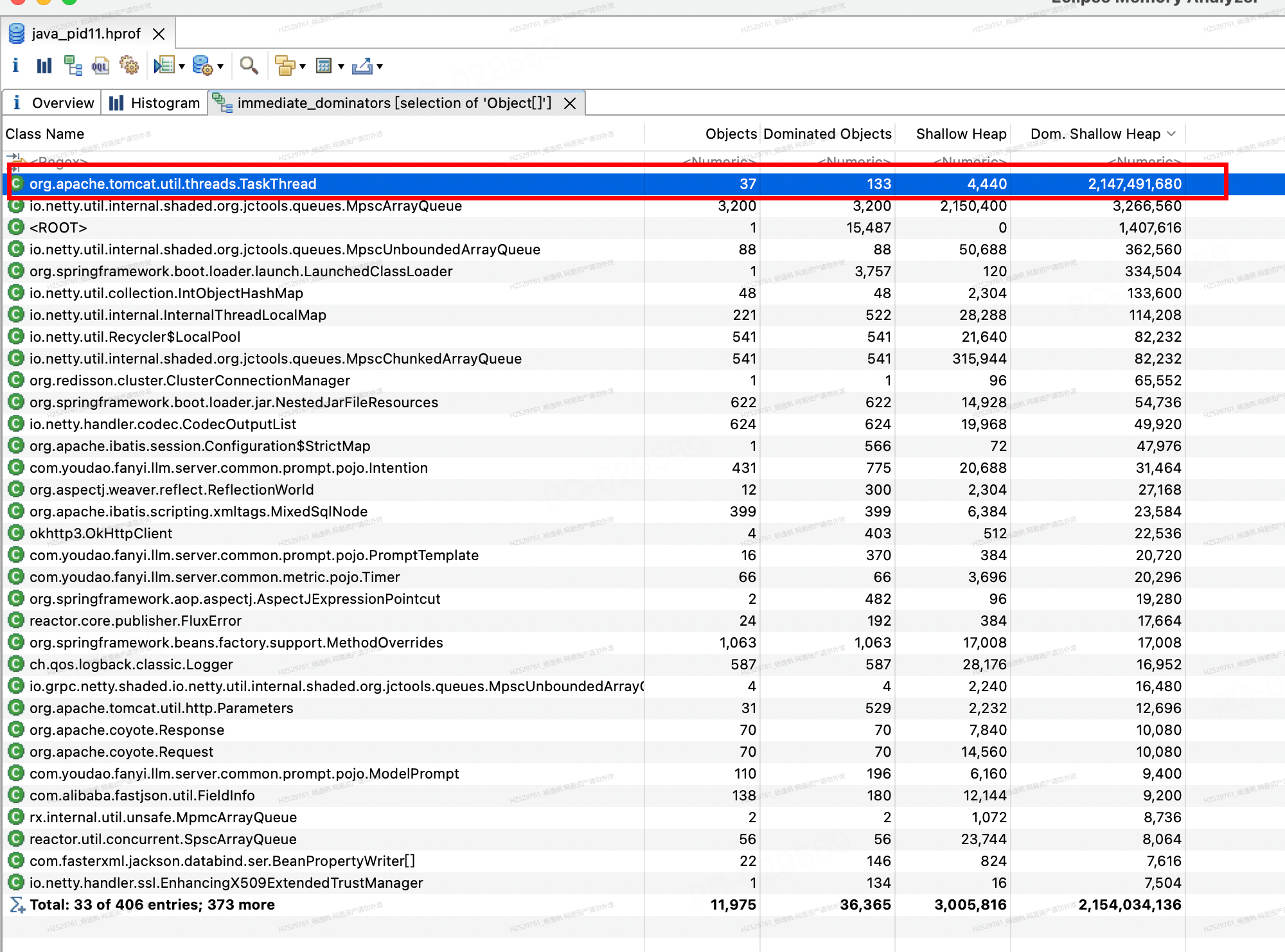
图14 Object[]类的immediate dominator
其中所选的那一行表示,TaskThread一共有37个对象,其中支配了133个Object[],并且TaskThread的本身对象大小(shallow size)是4440bytes,他支配的Object[]是2147491680bytes的大小
3.2.4 Leak report
Leak report会列举出可能存在内存泄漏的点,以及发生的栈信息位置
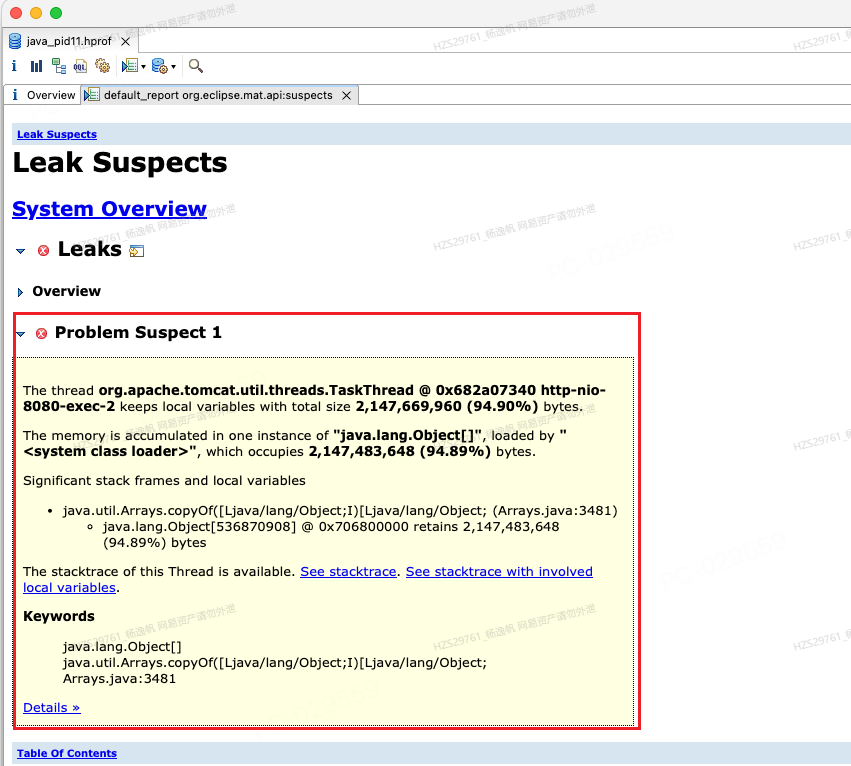
图15 Leak report
四、定位过程
根据在第一节所观察到的问题现象,我们从内存角度来分析GC停顿之间为何这么久?按照惯例,通常都会看一下内存中的大对象,因为大对象一般是造成内存出现问题的罪魁祸首,并且大对象也是最容易发现的。
4.1 查看大对象
jmap -hsito [pid] | head -n [num]
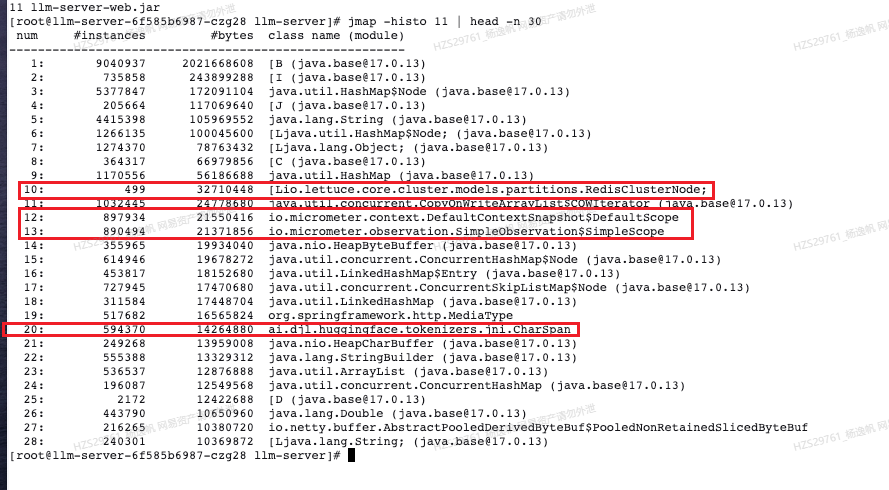
图16 小P老师服务某时刻大对象
大部分服务大对象前列就是byte、int等基本类型(不同的jdk版本可能会不同),也看不出什么门道。
通常先重点关注项目自己的包,再看一些引用的包。图16已经圈出了一些比较可疑的对象,但类比了同类稳定服务,第10行对象也是存在且现象一致的,于是就暂时排除他的嫌疑。
接下来就是12、13行这两个对象,他们用来做流式场景下线程之间上下文的自动传递,在github上看有人也提出了使用该组件的内存问题,我们把他列为可疑对象。
再接着就是20行这个对象,他是之前讲到的Huggingface组件,用来做大模型token计算。这个组件cpu占用率很高(之前性能自测过,图17)。那有没有可能在某个时刻计算量很大导致cpu激增,而容器分配的cpu不够用(而我们也确实发生了cpu抢占的情况),导致长期持有jvm对象而无法回收带来的GC卡顿,所以我也把他列为了可疑对象。
接下来我们来验证猜想。
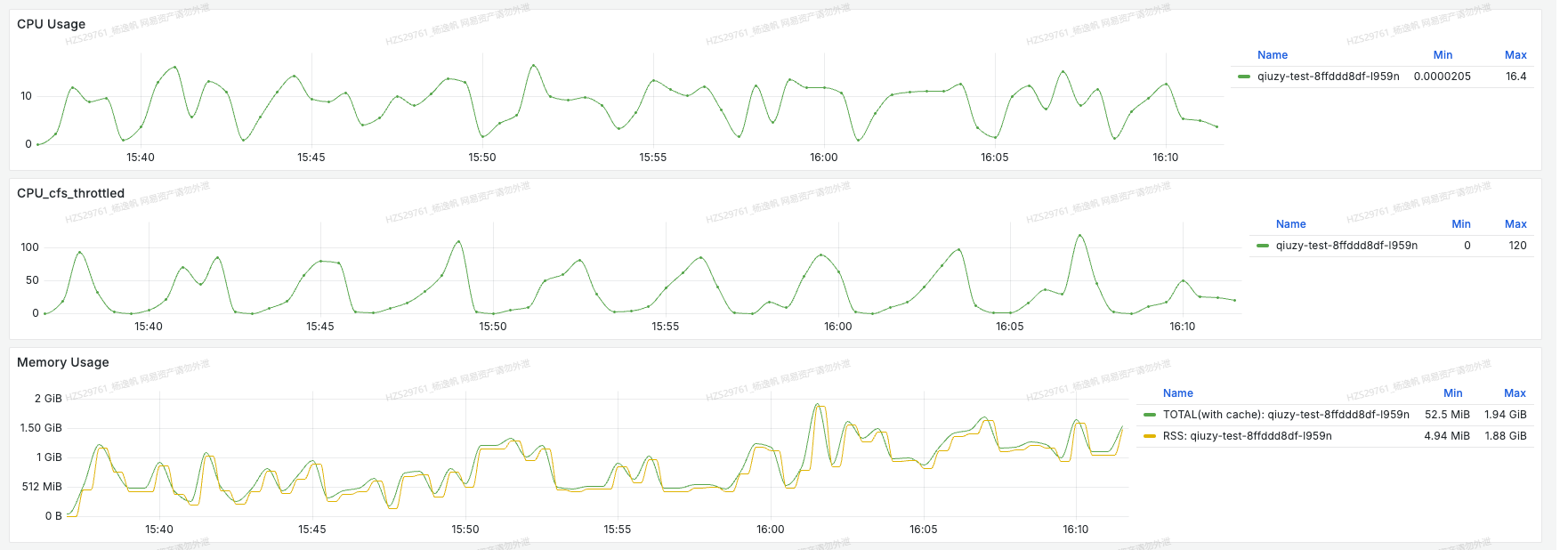
图17 Huggingface组件性能测试cpu、内存使用情况
4.1.1 验证猜想
我们将图16中,12、13行对象涉及的组件以及20行对象涉及的组件,分别打开/关闭来做性能测试,看 GC和jvm是否有明显变化,但当时并没有发现带来明显的jvm变化以及GC卡顿问题。那么问题可能出现在其他大对象上,这时候就需要把堆内存dump下来做分析了。
4.2 内存dump
根据我们之前观察的现象,old区域激增,一段时间后回落,这不太符合内存泄漏的现象,可能就是大对象被长期持有无法释放,于是在dump内存时,选择将堆里的对象全部dump而不仅仅是存活的对象。
jmap -dump:live,format=b,file=dump.hprof [pid]
4.3 使用MAT工具分析
注意一般堆文件多大,MAT内存就需要分配多大,修改方式参考。
MAT工具通常我们可以使用他从这几个角度分析:
- 堆内存中的大对象有些什么?
- 这些大对象为什么没被回收?看他的支配者:immediate Dominators,看他的GC root
- 这些大对象为什么这么大?看他支配了谁:retained set
4.3.1 导入堆文件
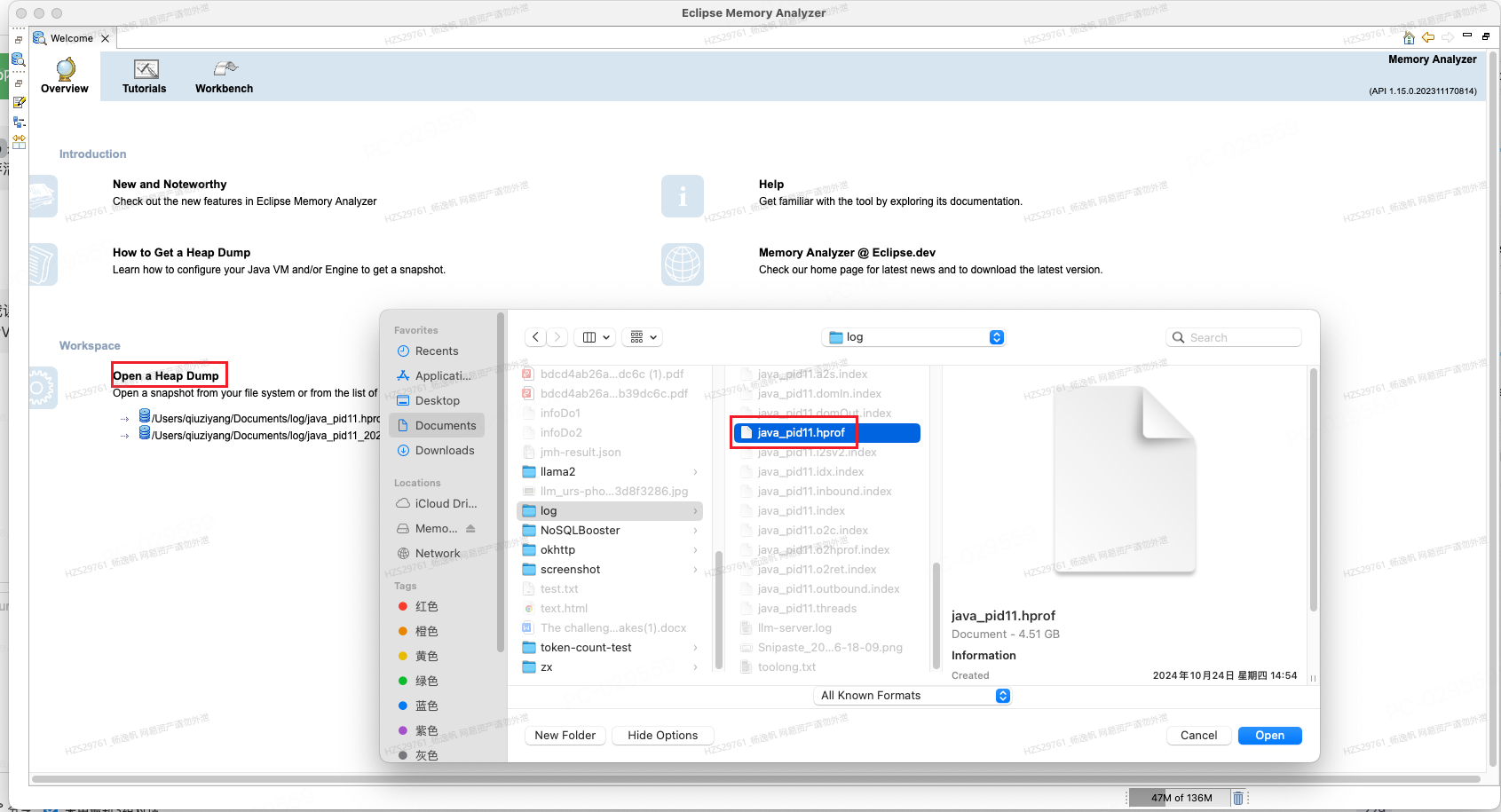
图18 堆文件导入示意图
4.3.2 查看大对象
使用Histogram查看大的对象(类),根据Retained Heap来排序(点击Retained Heap按钮就可以排序)
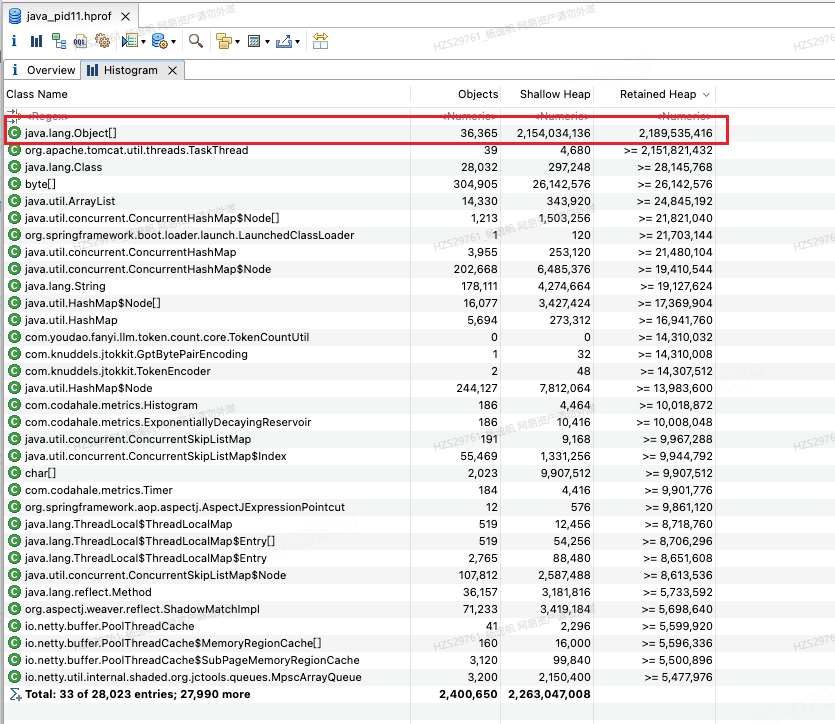
图19 堆文件大的对象(类)列表
发现最大的类是java.lang.object[],是一个数组,于是按照刚才思路我们先看他为什么没被回收?就看他的支配者。
4.3.3 查看大对象支配者
尝试看下这个大对象的支配者,看看是不是因为这个支配者应该被回收但是没被回收。
图20发现java.lang.object[]最大的支配者是TaskThread这个类,一共有37个对象实例,支配了133个java.lang.object[],TaskThread类本身大小是4440bytes,支配的对象java.lang.object[]大小是2147491680bytes。
其实看到这里已经没有意义了,因为他是处理http请求的线程,是不可能被回收的,但我们看一下这个TaskThread的GC Root ,看是否是被不小心创建出来的而没释放。
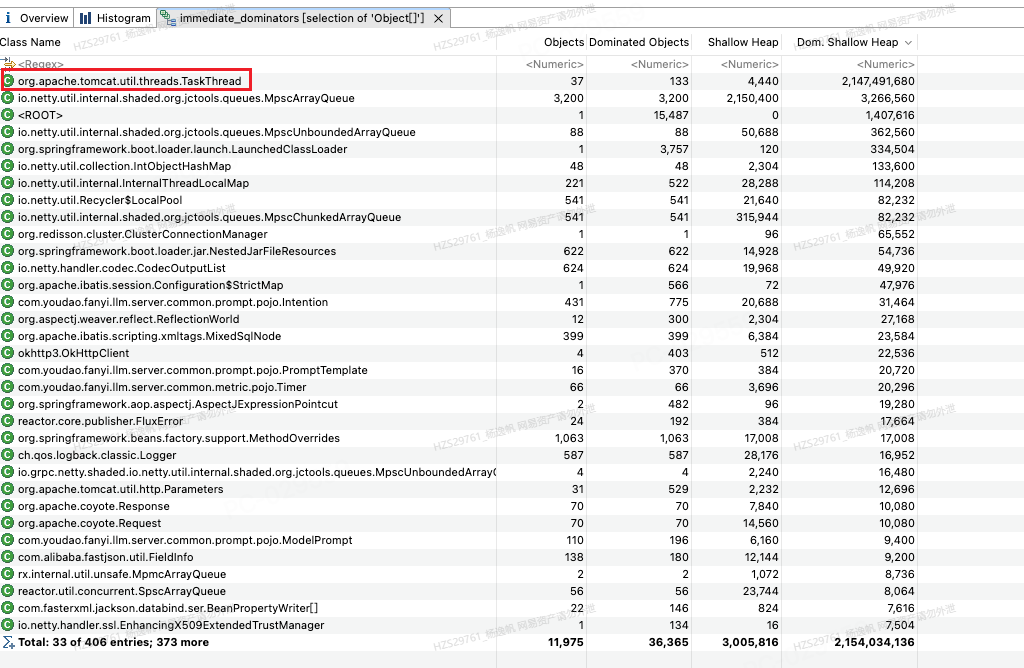
图20 java.lang.object[]的支配者
4.3.4 查看GC root
一般来说查看Gc root时都会选择 exclude weak/soft references,因为这两个引用肯会被GC掉,这是用来查内存泄漏的,但我们场景是对象是被长时间持有段时间无法回收,而不是一直无法回收。所以这里选择展现了所有的references。
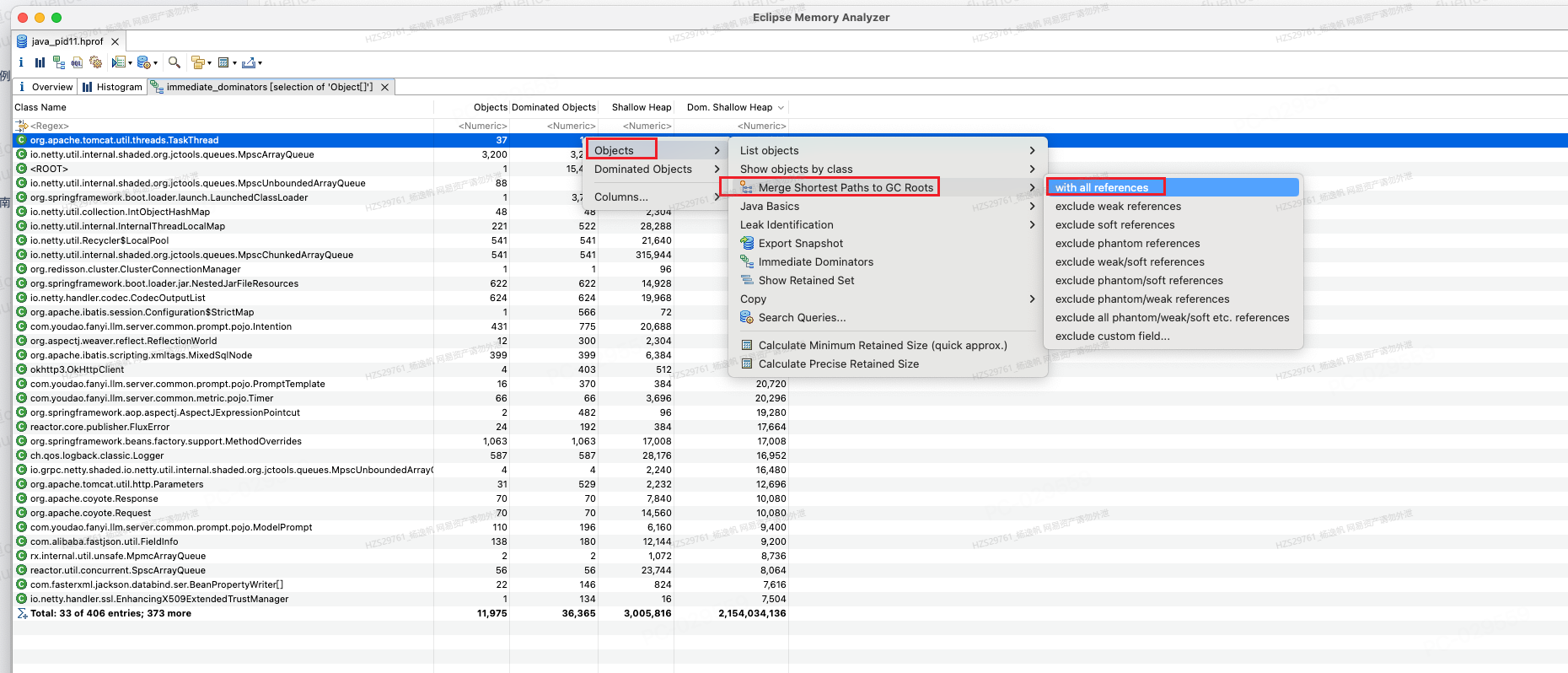
图21 查看TaskThreadGC root示意图
从图22来,TaskThread都是tomcat创建的线程用来处理http请求的,http-nio-8080-exec-2支配了很大的对象,那就是刚才java.lang.object[],这种被线程支配的对象,大概率是临时变量,也就是方法栈里创建出来的变量,http-nio-8080-exec-2是不可能被回收的。
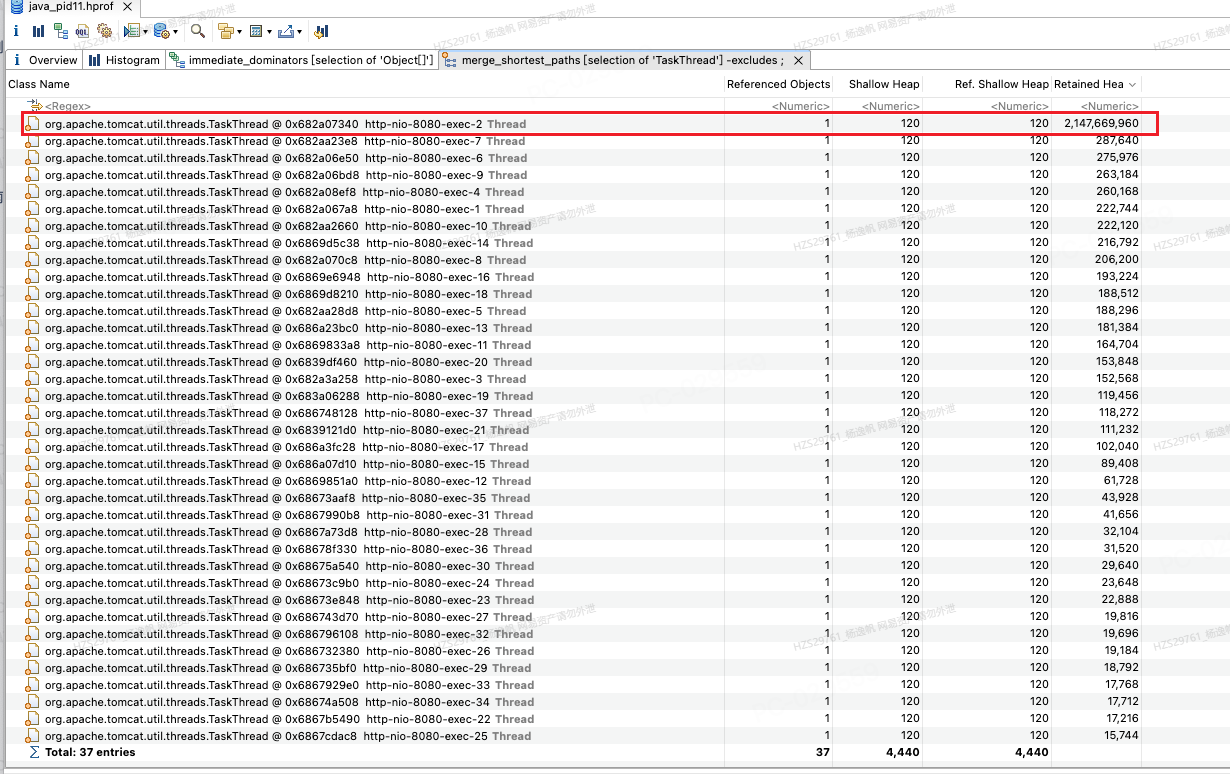
图22 TaskThreadGC root
但是临时变量的回收,会在方法执行完,对他引用没有了之后进行。因为我们dump某一个时刻的堆栈信息,可能线程没有执行完,没被回收也是正常的。但是在http所有的线程中,只有这个线程持有很大的对象明显是不合理。于是我接着看 java.lang.object[]对象为什么这么大?
4.3.5 查看retained set
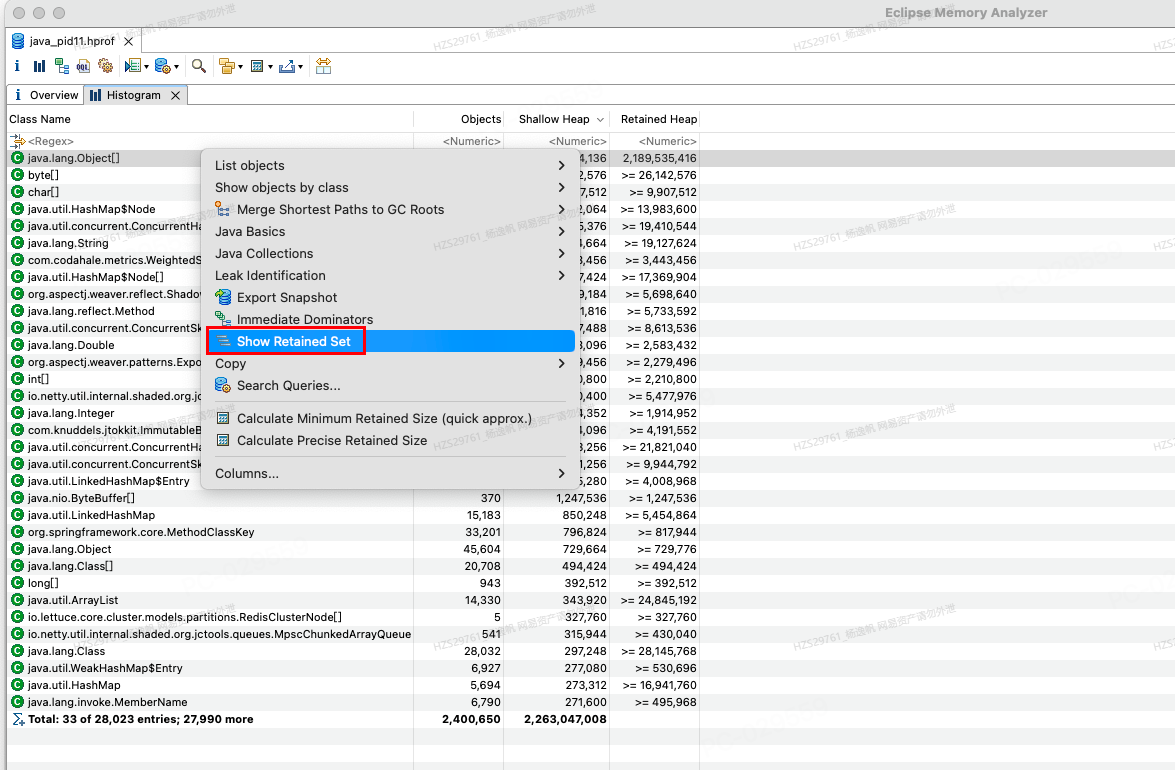
图23 查看java.lang.object[]Retained Set示意图
查看java.lang.object[]Retained Set可以看出他支配了哪些对象/类,就可以知道他为什么这么大(retained set是包含本身的)
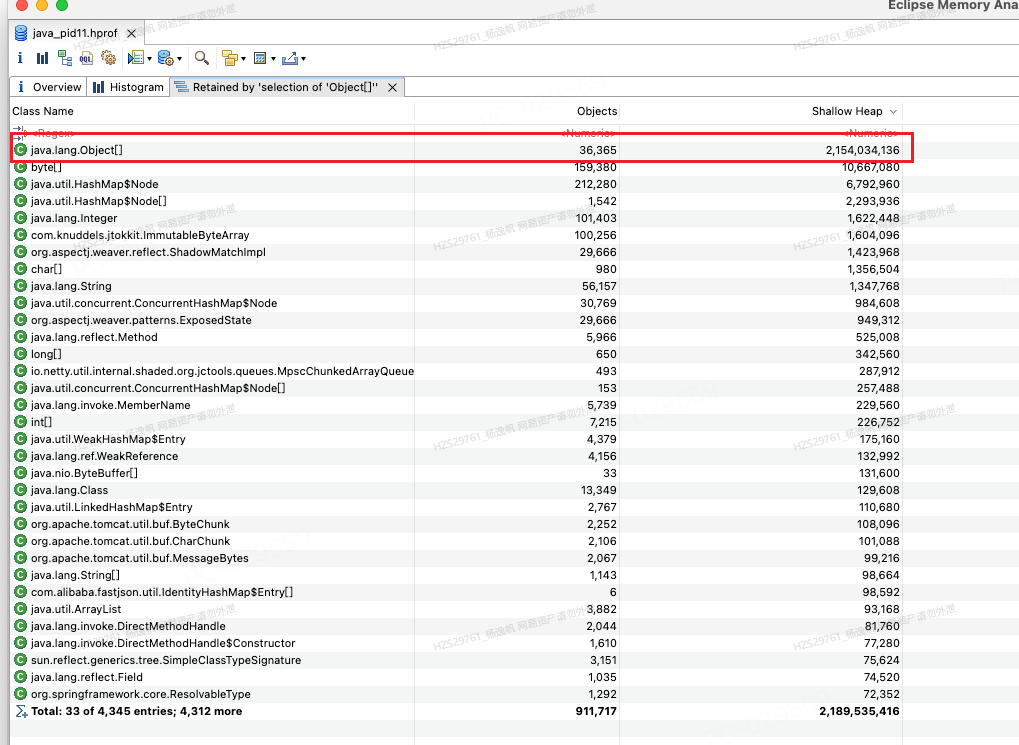 图22.png
图22.png
图24 java.lang.object[]Retained Set
从图24可以看出,在其所有支配的对象中,其本身是最大的,到这里好像陷入了死结。
这个对象被谁支配?是一个线程。这个对象为什么这么大?是因为他本身就很大。
但回想起刚才说的,这个对象被http线程支配,因为线程没有执行完,引用没消失所以一直存在,于是我就想能不能看一下这个线程的栈信息,正好MAT中也有这样的功能。
4.3.6 查看栈信息
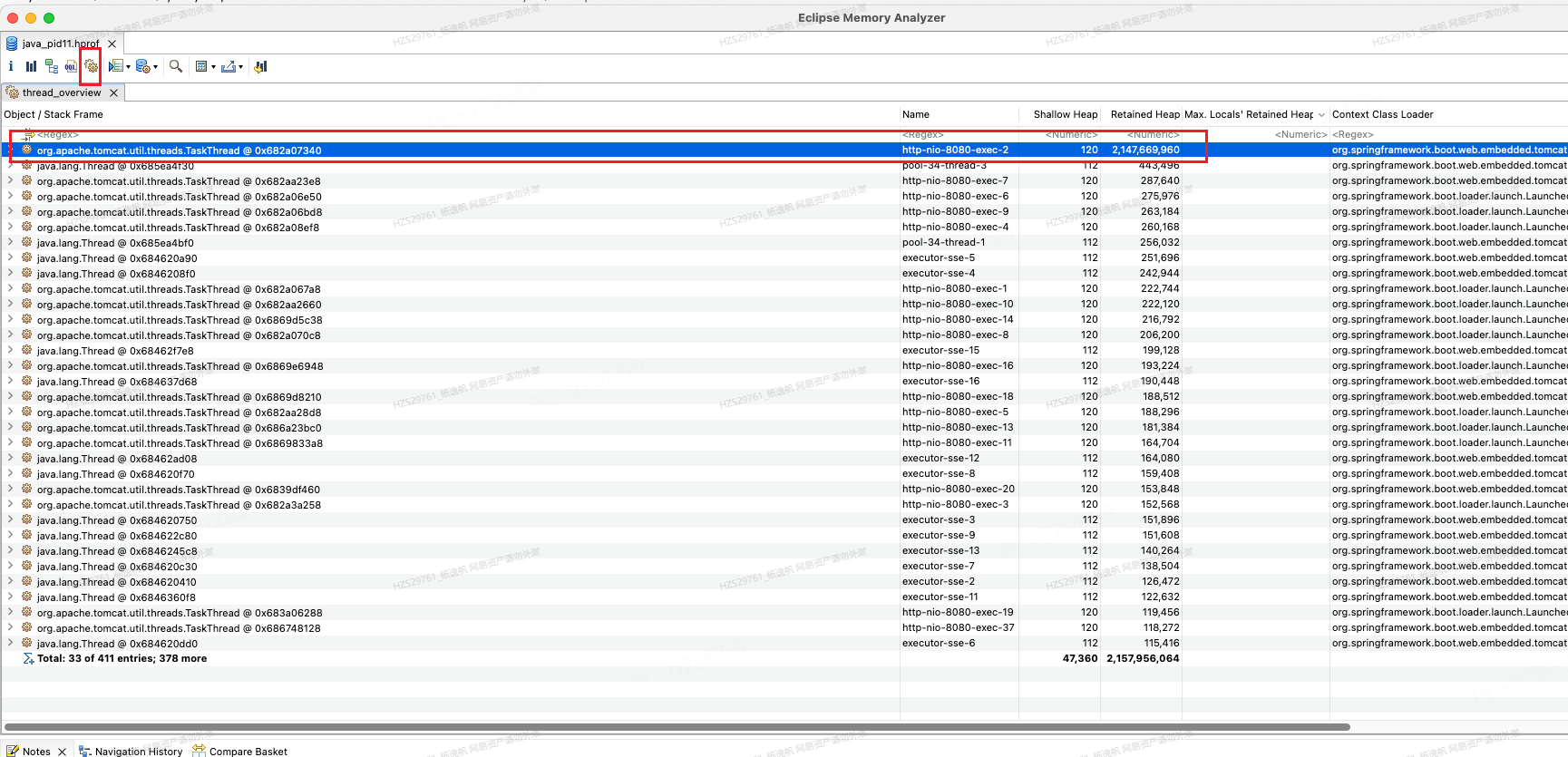
图25 所有线程的栈信息
从图25来看,http-nio-8080-exec-2占用了很大的retained heap,就接着点开来看就是整个线程的堆栈情况(不排序的话默认就是执行路径)
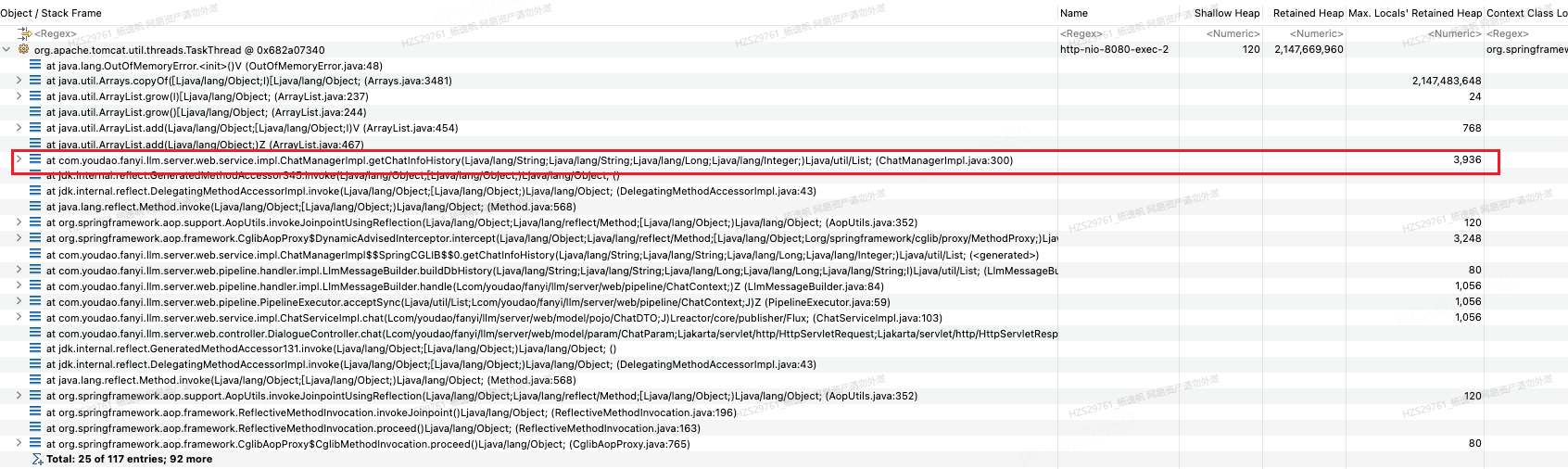
图26 http-nio-8080-exec-2堆栈信息
看堆栈信息,一般来说是从上到下找到首个业务代码进行分析,从图26可以看出从业务代码ChatManagerImpl.java:300处添加一个元素到列表,最后触发了容器扩容,最终导致OutOfMemoryError。并且这个线程在执行copyOf时持有很大的内存大小Max Local Retained Heap(本地变量保留大小),已经定位到业务代码了,接下来就根据业务代码去看看原因。
4.3.7 跟踪业务代码
1 | public List<ChatInfoDO> getChatInfoHistory(String userId, String taskId, Long parentChatId, |
在分析可疑点之前,我先简单描述下这段代码所做的事情。
在小P老师对话场景中,是采用一问一答的形式,例如下方图27所示,蓝色表示用户,淡红色表示系统回答。
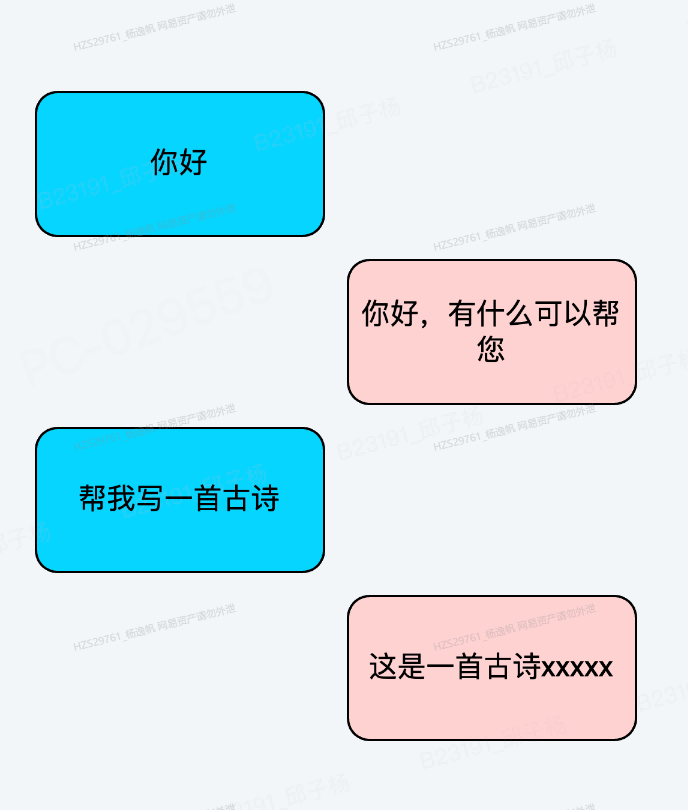
图27 大模型对话示意图
为了让模型更好的理解用户问题,通常我们会像图26所示,携带所有的历史消息送给模型。当前业务代码就是找到用户的历史对话然后构建起来提供给模型。
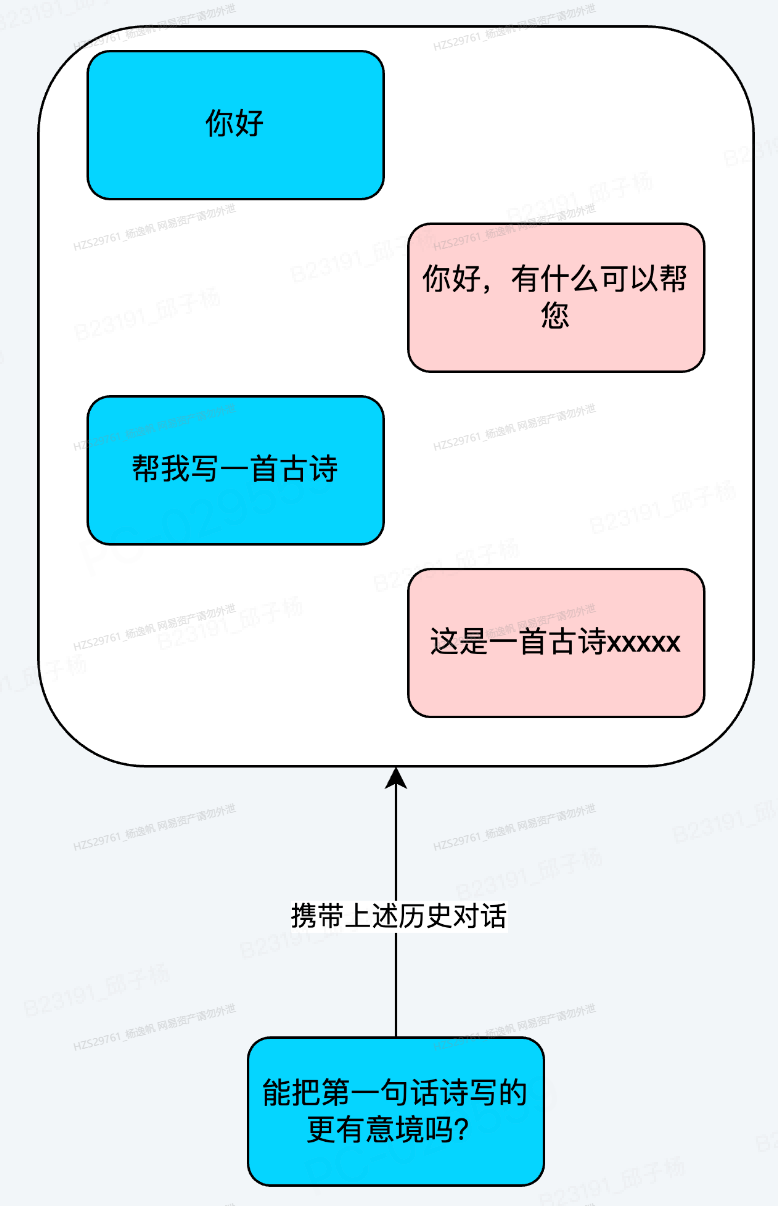
图28 携带历史对话示意
如图29所示,我们给每个消息两个属性id=xxx、parendId=xxx,这样来呈现一种父子关系,用户输入消息时生成id,并通过传入的parentId=3向上寻找消息,找到id=3的消息,循环寻找,直到parentId=-1
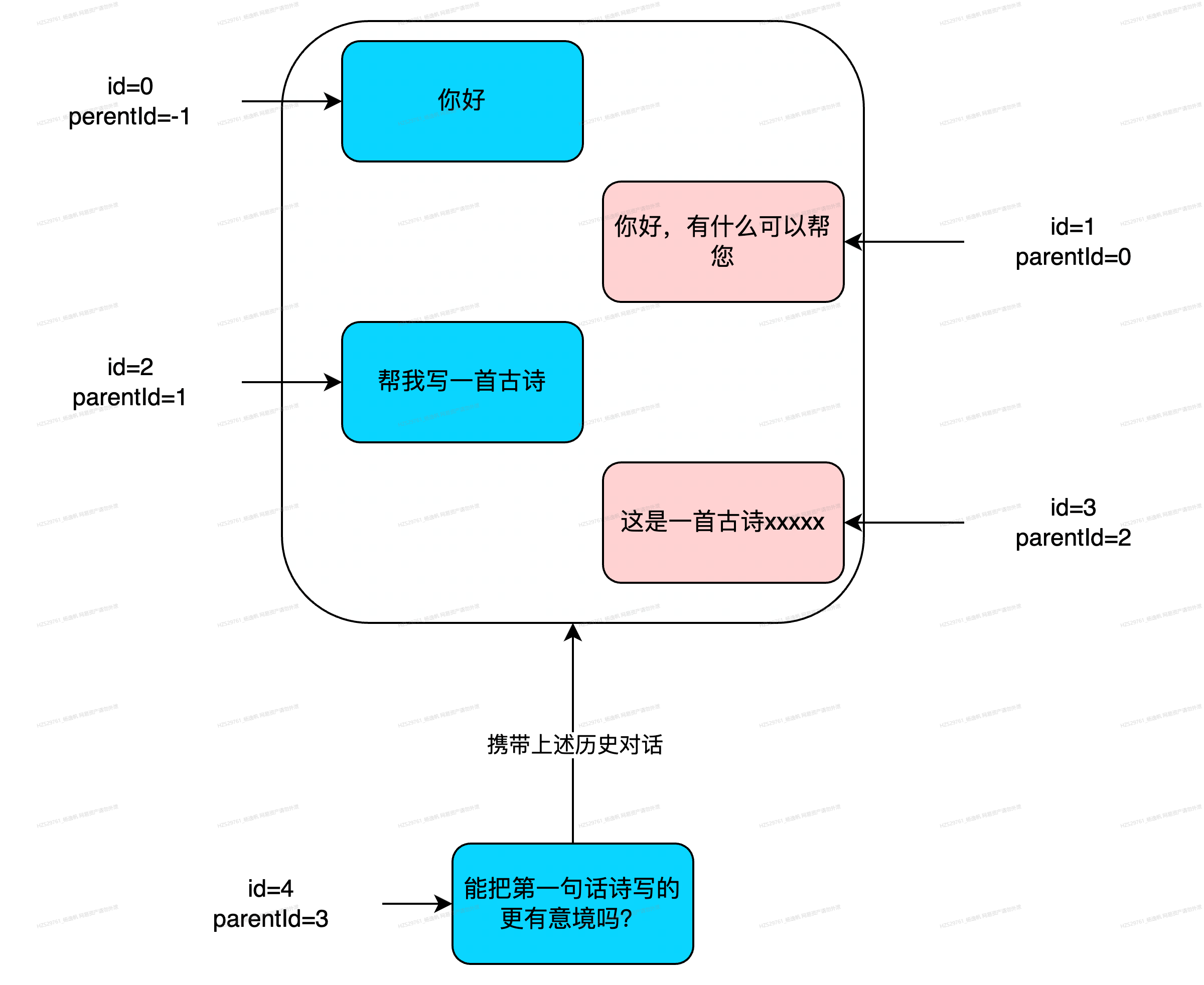
图29 构建历史对话示意图
回过头我们来看业务代码,标记1就是栈信息所示的位置,这处代码其实有一个很明显的风险点while循环构建链表,同时结合我们的对象是一个大数组,那这个while循环就很可疑。结合刚才业务代码逻辑的分析,我当时想到了以下可疑点:
- 一个消息的id和parentId一致发生了循环,导致死循环
- chatInfoDOMapper.selectChatHistory()从数据库查出来的数据量很大
接着看了数据库查询语句chatInfoDOMapper.selectChatHistory()不可能发生查出很多数据的问题。
那么现在最可疑的就是消息循环了,本来分享到这就结束了。要去查数据库看看有没有id和parentId重复的数据了,但因为当时是和同事们在分享这篇文章,同事们就提出了两个问题。
- 有没有可能是两个消息发生了循环?消息A找到了消息B,消息B又找回了消息A。
- MAT可以看这个链表里有啥吗?以及能不能看这个对象的值,不然查库可能会很慢。
很显然第一个是很有可能的。 第二个问题因为对MAT还是初次使用所以不太了解,但在同事的引导下,我们尝试看链表里具体的数据是什么样子。
4.3.8 查看栈具体用了哪些对象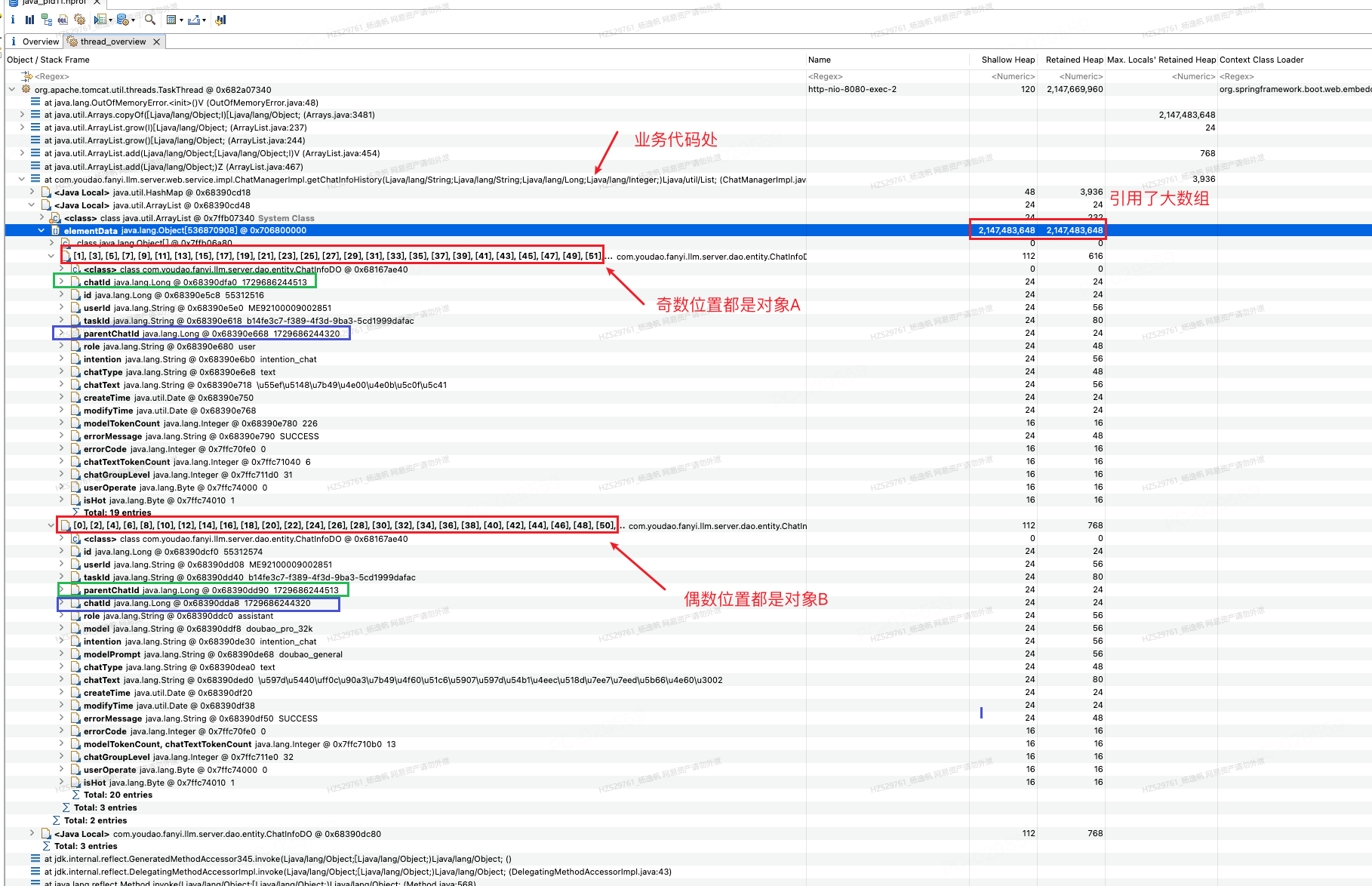
图30 栈的临时变量
如图30所示,我们继续点击业务代码方法栈点,就可以看到这个方法栈点引用了(注意是引用不是支配)HashMap、ArrayList、ChatInfoDO,因为根据业务代码分析可能是ArrayList膨胀,所以继续点击ArrayList可以看他引用的元素elementData,包括了object[]、ChatInfoDO。这里问题就展现出来了,如图30红框所示,ArrayList奇数位置[1],[3],[5]…都是ChatInfoDO_A,偶数位置[0],[2],[4]…都是ChatInfoDO_B,并且再次点击ChatInfoDO_A和ChatInfoDO_B就可以看到他们的chatId、parentChatId,这时候看到他们确实互为引用了,如图31所示。
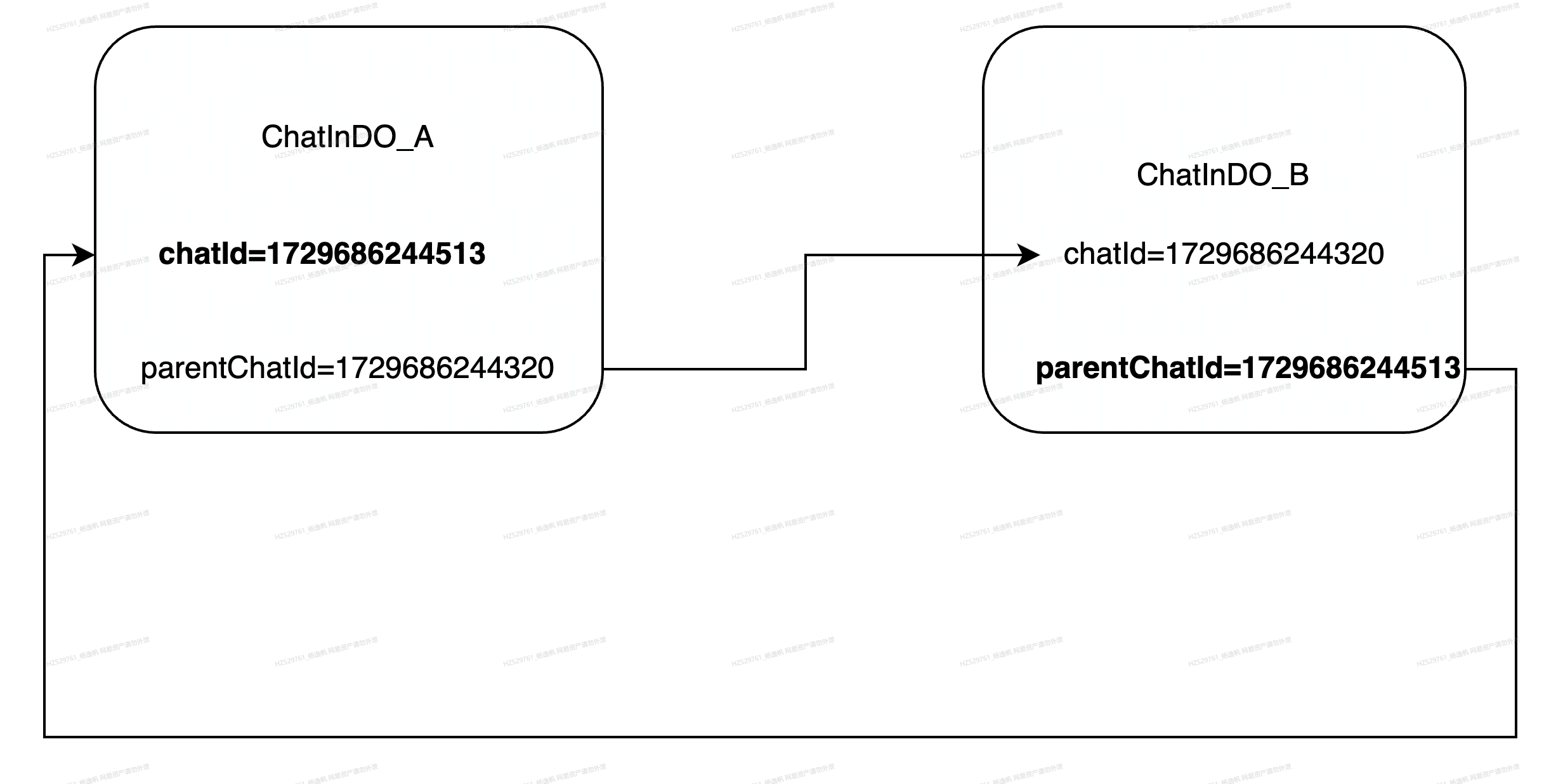
图31 互为引用的消息
至此问题原因顺利找到。
后续分析还发现,不仅是两个消息会循环,多个消息也会循环。历史消息构建其实是单链表从尾到头的构建过程,找到头节点就停止,但某个位置产生了环就导致悲剧。所以得出一点建议:之后while的使用一定得注意!!!。
虽然原因找到了,但为什么产生重复的Id呢?我们设计的Id可是唯一的!于是我们又分析了生成Id的代码。
4.4 分析ID重复的原因
1 | public class IDGeneratorUtil { |
因为小P老师服务是分布式服务,有多个节点,需要保障消息唯一Id。常见唯一Id方式很多:UUID、雪花等等,但基于我们的考虑并没有使用上边的方式。
当时在设计唯一Id时主要考虑以下几点:
- 具有时间性
- 生产效率高
- 符合数字需求
于是就通过时间戳来体现时间性,在加一个全局唯一的循环数,这样是不是具有符合上述的要求了?
但在大家的分析下发现了这样一个BUG,假如当前时间是10,随机数是10,过了一段时间后当前时间是19,随机数已经发生循环变成了1,这样两个Id是不是都一样变成20了(但概率确实很低!!!)
到此终于真相大白了!
五、 总结
分析过程其实是坎坷的,总结的时候,已变成已知答案寻找答案的过程,所以看起来会很顺畅。
问题千奇百怪,分析过程也千奇百怪,但总结了一些小经验。
- 监控jvm内存或者可以观察jvm是比较重要的
- GC日志也是比较重要的日志
- 内存问题一般可以从大对象着手,分析对象为什么这么大?为什么没被回收?
- MAT的Histogram、Dominator Tree看大对象
- MAT的Immediate Dominators看大对象被谁直接支配而没回收
- MAT的retained set看大对象支配了哪些,导致他这么大
- MAT的线程分析,来分析线程持有对象特别大的情况,分析栈信息
当然,在问题处理的过程中,还有一些不可忽视的细节操作,对排查问题至关重要。
- 如何抓取偶现问题的JVM dump现场?
- 只有内存泄漏才会引起内存使用率升高吗?
- 如何分析GC日志数据,推断问题原因?
基于篇幅有限,本文不再赘述,后续会编写系列KM文章,为大家带来实践中走过的弯路与总结的小技巧。