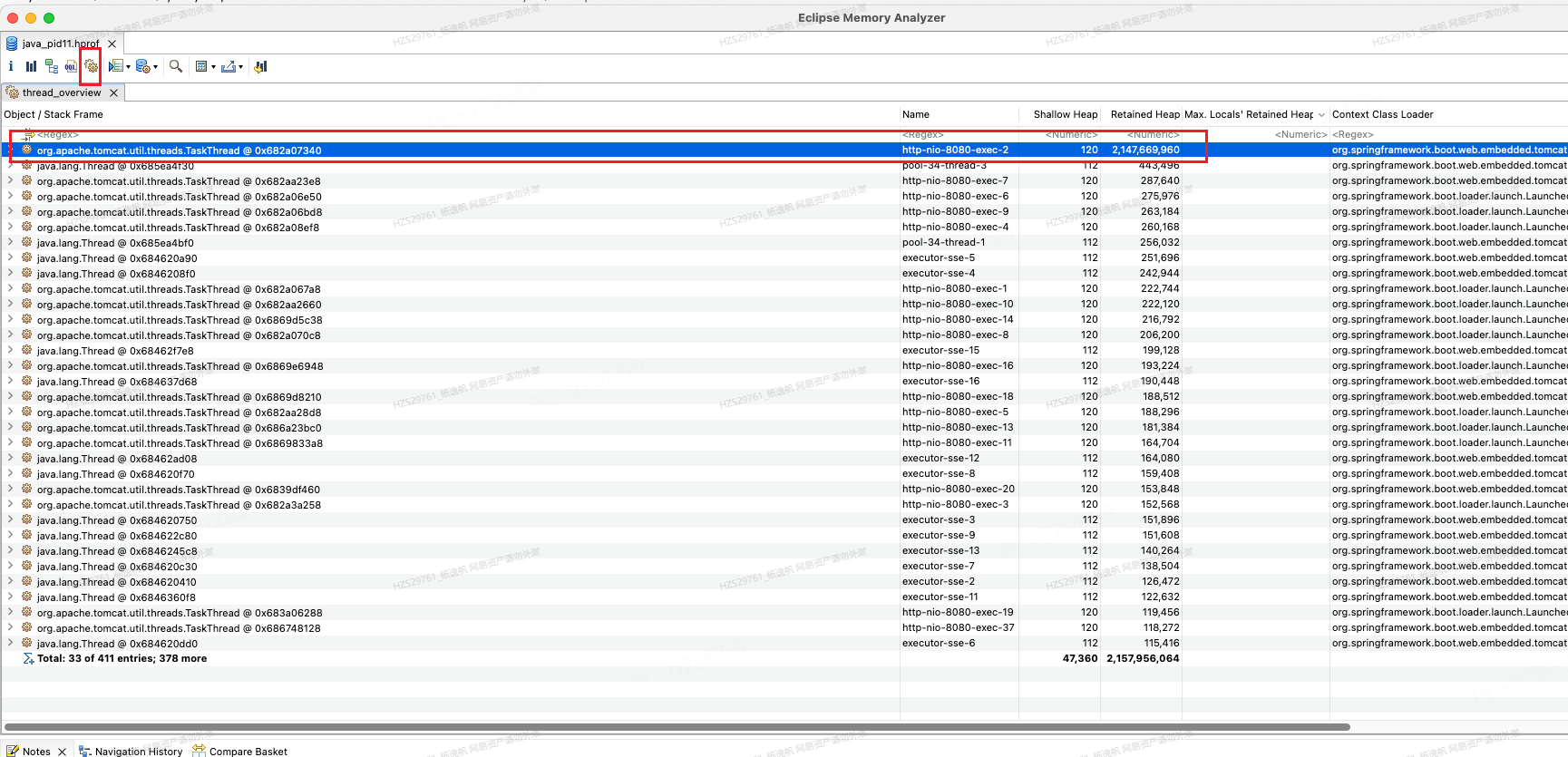
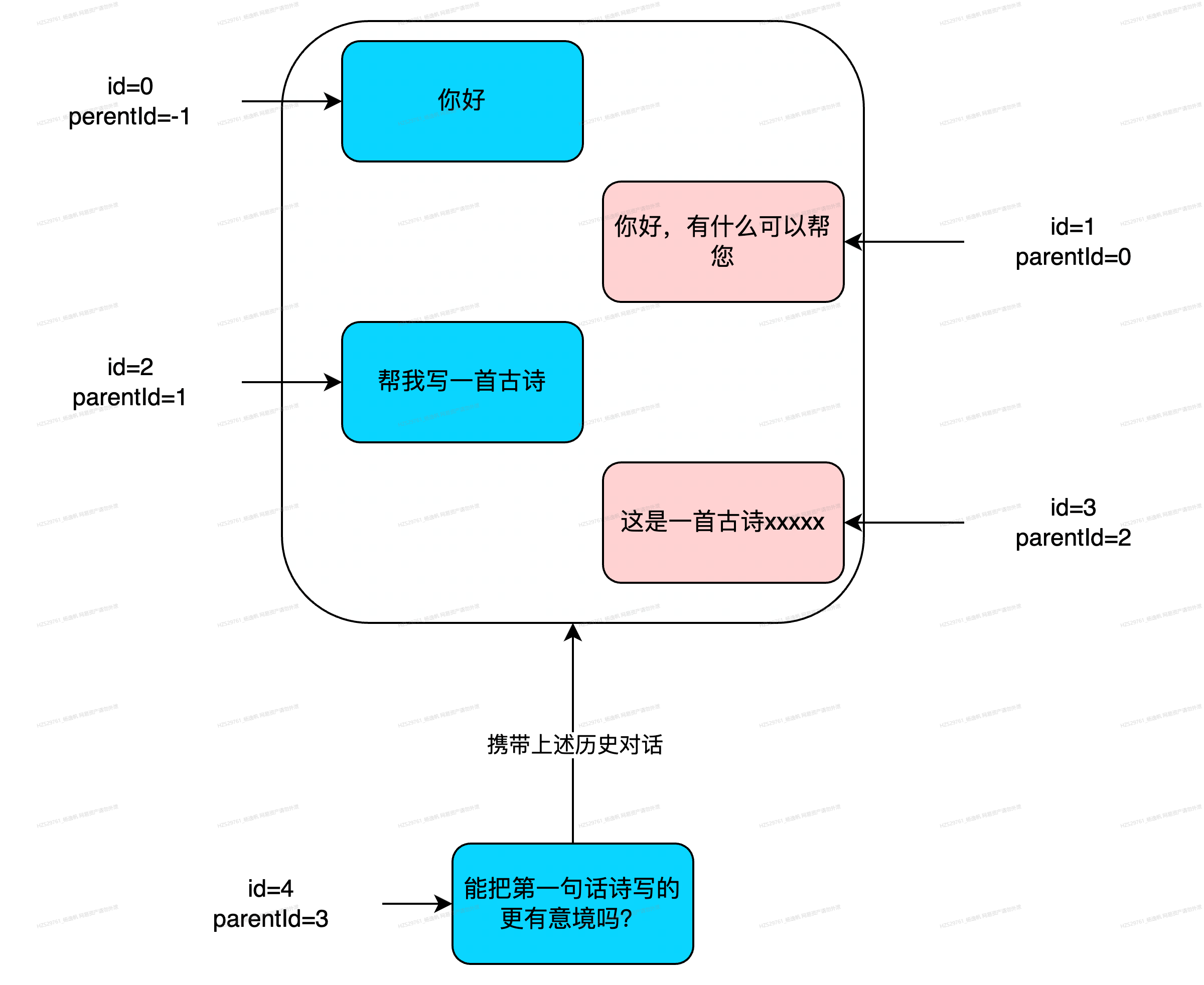
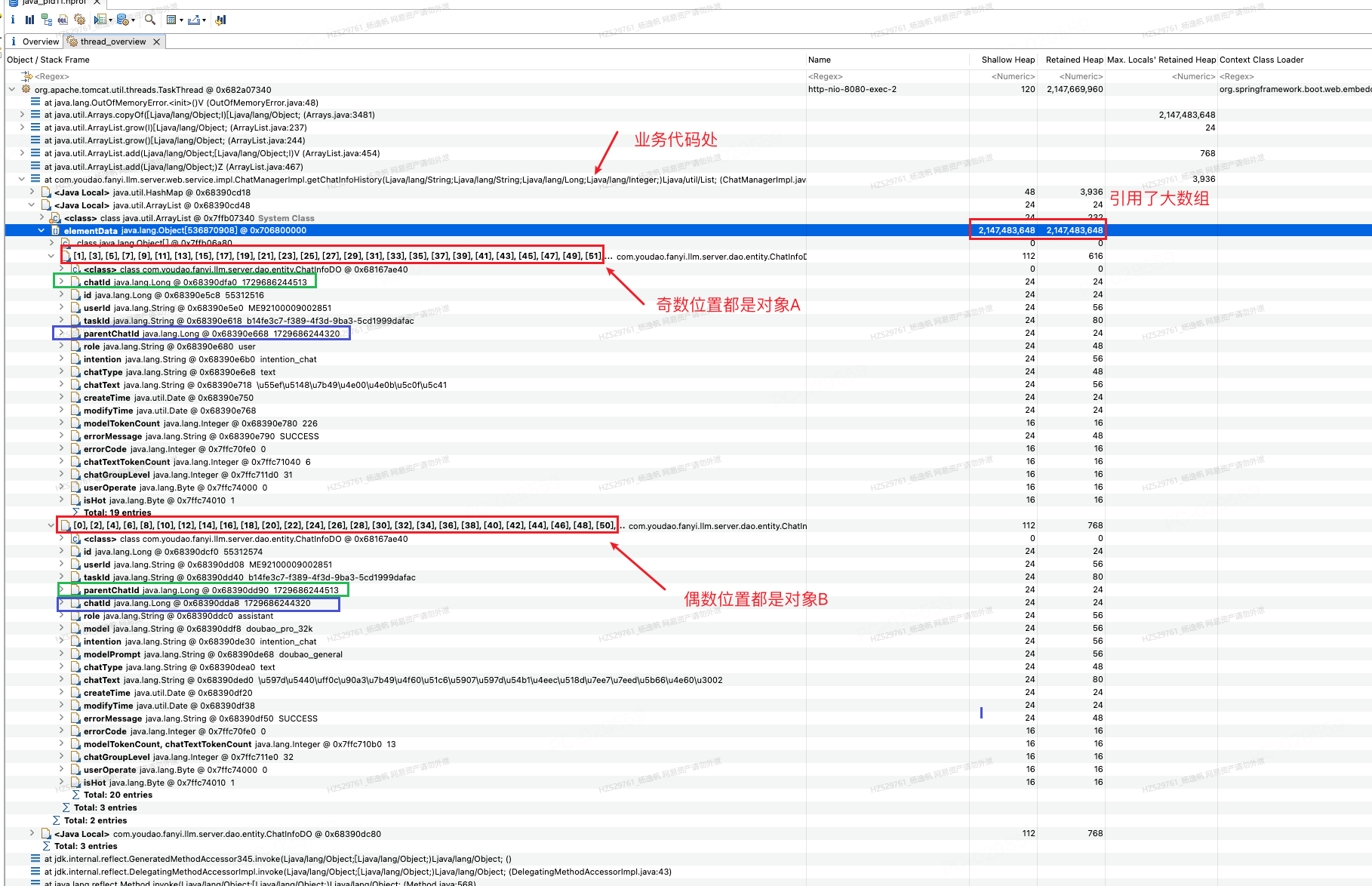
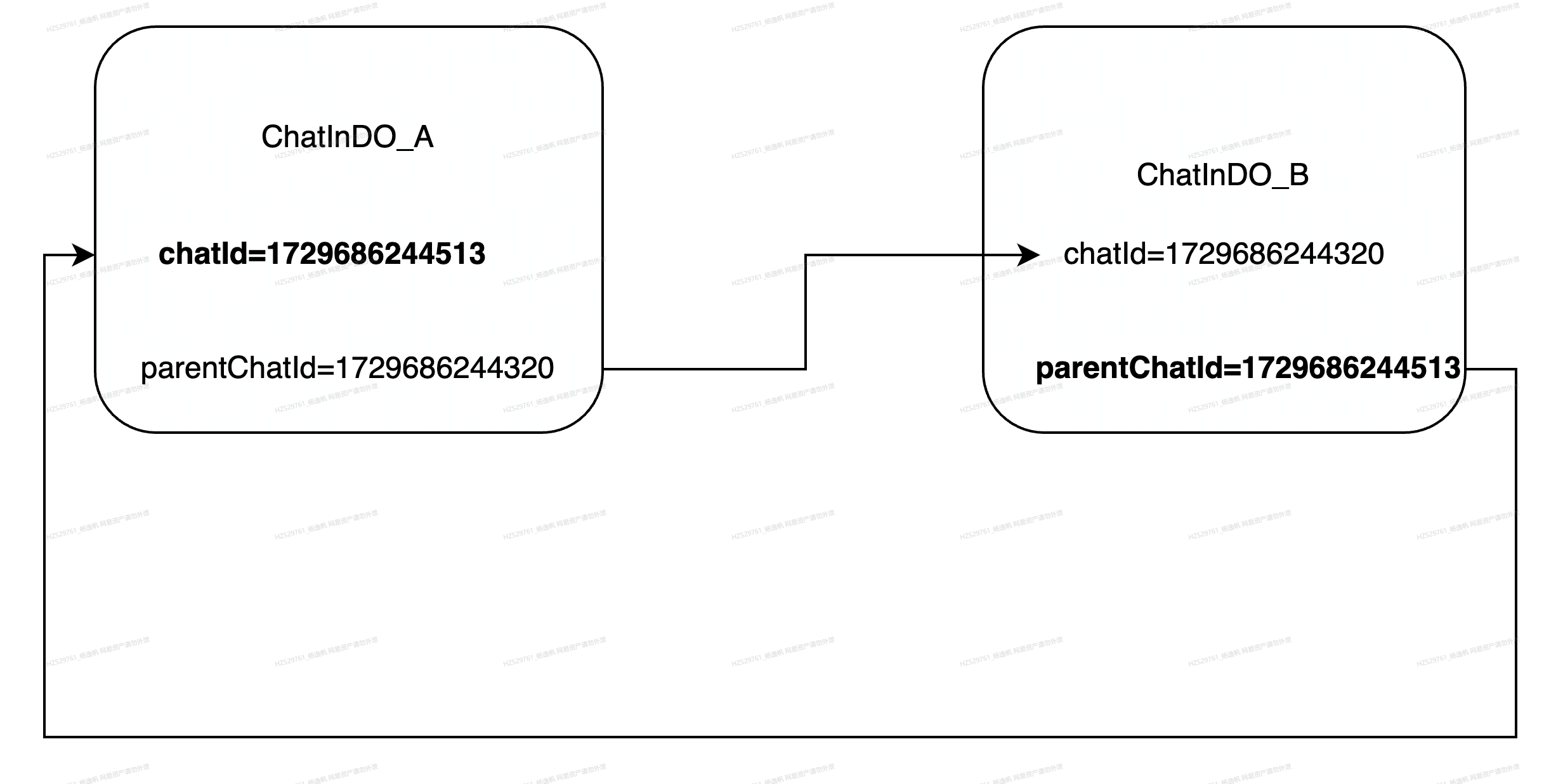
1. blockchain4agent交互
角色
职责
流程拆解引擎 (Engine)
生产者 (Producer)。只负责发任务(写链)和最后验收(写链)。不再管分发。
智能合约 (Contract)
公告板 (Broker)。维护任务池状态(待领取、进行中、待验收)。
Agent Driver
消费者 (Consumer)。主动监听链上事件,发现适合自己的任务直接调 claim抢单。
OSS
数据仓库。存放大文件,链上只存 URL。
1.1. 流程拆解引擎
1.1.1. 基于链上注册表的工作流编排 (Workflow Orchestration)
系统的核心是一个智能的任务拆解引擎,它负责连接用户的自然语言输入与链上的去中心化执行资源。
- 动态能力匹配:
- 当用户输入 Prompt 时,拆解引擎首先会读取链上 Agent 注册表 (On-chain Registry)。
- 引擎会实时获取当前可用的 Agent 类别(Capabilities),例如“文生文 (Text-to-Text)”、“图生图 (Image-to-Image)”、“图生文 (Image-to-Text)”等。
- 基于这些实时供给信息,引擎将用户的复杂需求拆解为一组可执行的子任务序列(Sub-tasks)。
- 链上任务分发:
- 拆解完成后,引擎将针对不同的子任务类别,精准调用对应的任务分类智能合约 (Task Category Contracts)。
- 例如,生成的“图像优化”子任务会被发送到 ImageTaskContract,由该合约广播事件,供对应的 Driver 抢单执行。
1.1.2. 可视化交互与状态追踪 (Visualization & Observability)
为了提升用户体验,前端展示将采用类似 ComfyUI 的节点流式界面,实现全链路的透明化与可观测性。
结构化拓扑输出 (DAG JSON):
引擎在拆解任务的同时,会生成一份描述任务拓扑结构的 JSON 数据(Directed Acyclic Graph, DAG)。
这份 JSON 不仅包含任务的依赖关系(如:先生成文本,再基于文本生成图片),还包含每个节点的元数据(Task ID、预期执行的 Agent 类型)。
实时流程渲染:
前端解析该 JSON,渲染出可视化的任务节点图。
用户可以直观地看到:
执行路径:任务是如何一步步流转的。
执行主体:当前节点是由链上哪个具体 Agent(显示为钱包地址或别名)在执行。
实时状态:每个节点的状态变化(Pending -> Processing -> Completed/Failed)会实时映射在 UI 上。
1.1.3. 可靠性工程与演进策略 (Reliability & Evolution)
系统的最终效果强依赖于“任务拆解引擎”的决策质量。为了确保系统的稳定性和可衡量性,我们采取分阶段落地的策略。
阶段一:固定模版 (Static Templates / MVP)
策略:前期不做完全开放的动态拆解。我们预设几套经过验证的高频任务流模版(例如:“小红书文案生成流”、“Logo 设计流”)。
优势:降低不可控风险,确保用户只要输入合规的 Prompt,必然能跑通流程。同时便于测试链下 Driver 与链上合约的交互稳定性。
阶段二:评估体系与动态化 (Evaluation & Dynamic Planning)
指标建设:建立一套衡量“拆解合理性”的指标体系(Metrics)。
成功率:整条链路跑通的比例。
一致性:不同 Agent 组合对同一任务的执行效果评分。
人工反馈 (RLHF):用户对最终结果的点赞/点踩,用于反向优化拆解引擎。
动态规划:在模版稳定的基础上,逐步引入 LLM 进行动态任务规划,实现真正的“意图识别 -> 自主编排”。
1.2. 智能合约
1.2.1. 核心状态机设计 (State Machine)
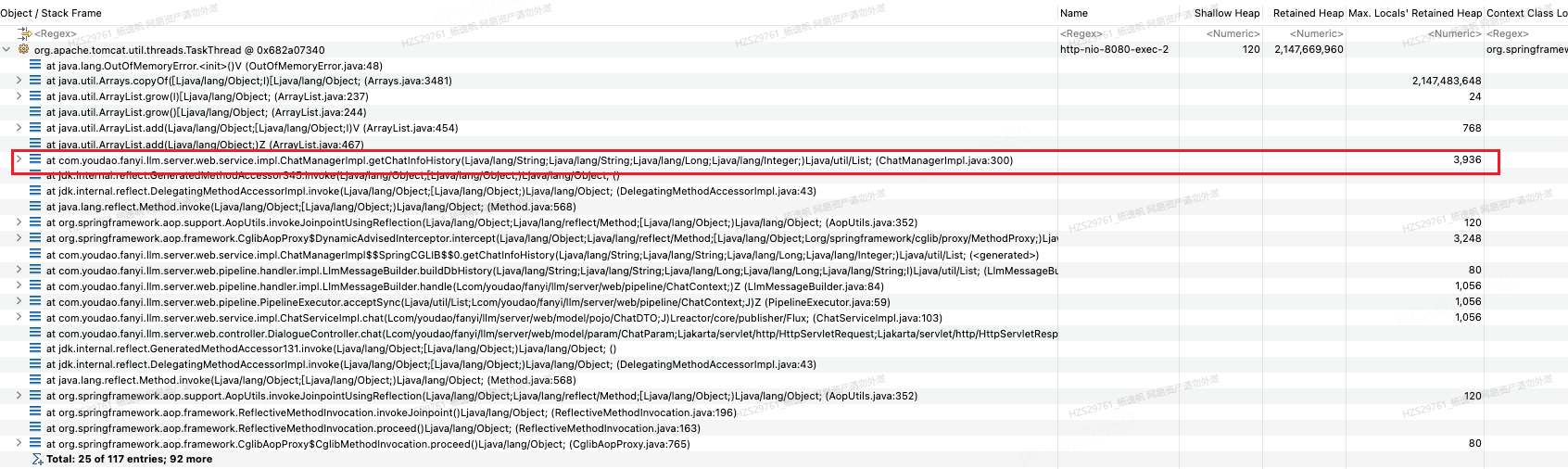
Driver 是定时的、主动抢占的,所以状态 (Status) 是 TaskSheet 中最重要的字段。我们需要定义一个严谨的生命周期枚举:
enum TaskStatus {
PENDING, // 0: 待领取 (任务刚创建,Driver可抢)
ASSIGNED, // 1: 进行中 (已被Driver抢到,锁定中)
SUBMITTED, // 2: 待验收 (Driver已提交OSS链接,等待引擎确认)
COMPLETED, // 3: 已完成 (引擎验收通过,准备分账)
FAILED, // 4: 失败 (Driver放弃或执行出错)
TIMEOUT // 5: 超时 (Driver抢了但没在规定时间内提交,重置为PENDING或人工介入)
}
1.2.2. 智能合约数据结构设计
1.2.2.1. 代理人注册表 (AgentRegistry)
关键流程:
Web2 阶段:Agent 在你们的网页端注册账号、密码,你们的后台生成一个钱包私钥给到 Agent(或者 Agent 自己生成公钥给你们)。
Web3 阶段:Agent 拿到钱包和私钥后,必须由 Agent 的 Driver 程序主动发起一笔交易 调用合约,将自己的元数据(API地址、能力标签)写入链上。这代表了“我拥有这个私钥,且我准备好接单了”。
主要变化点:
新增 registerSelf 接口:允许 Agent 携带质押金(可选)自助上链。
新增 updateMyself 接口:Driver 的 IP 或 API 地址变动时,不需要求管理员,自己发交易修改。
状态流转:自助注册后,状态默认为 PENDING 或 ACTIVE(取决于你们的风控策略,代码中设定为默认激活但管理员可封禁)。
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import “@openzeppelin/contracts/access/AccessControl.sol”;
contract AgentRegistry is AccessControl {
// 角色定义
// MANAGER_ROLE: 平台管理员,拥有“生杀大权”,可以封禁恶意 Agent
bytes32 public constant MANAGER_ROLE = keccak256(“MANAGER_ROLE”);
// Agent 详细档案
struct AgentProfile {
string name; // Agent 名称 (如 “DeepSeek-Coder-01”)
string endpoint; // Driver 的 API 回调地址 (如 “https://driver.agent.com/api“)
string[] capabilities; // 能力列表 (如 [“text-to-code”, “audit”])
uint256 stakeAmount; // 已质押的金额 (ETH/Token)
uint256 registerAt; // 注册时间
bool isActive; // 账户状态 (true=正常接单, false=被封禁或暂停)
address walletAddr; // 冗余存储,方便遍历
}
// 核心存储: 钱包地址 => 档案
mapping(address => AgentProfile) public agents;
// 辅助数组: 用于前端展示所有 Agent 列表
address[] public agentList;
// 快速查询: 避免重复注册
mapping(address => bool) public isRegistered;
// 事件
event AgentRegistered(address indexed agentWallet, string name, uint256 stake);
event AgentUpdated(address indexed agentWallet, string newEndpoint);
event AgentStatusChanged(address indexed agentWallet, bool isActive);
constructor() {
_grantRole(DEFAULT_ADMIN_ROLE, msg.sender);
_grantRole(MANAGER_ROLE, msg.sender);
}
// ==========================================
// 1. Agent 自助操作接口 (Driver 调用)
// ==========================================
/**
@notice Agent 自助注册函数
@dev Agent 必须用分配给它的私钥签名并发送此交易
@param _name Agent名称
@param _endpoint Agent服务的访问地址 (http/https)
@param _capabilities 支持的任务类型列表
*/
function registerSelf(
string calldata _name,
string calldata _endpoint,
string[] calldata _capabilities
) external payable {
require(!isRegistered[msg.sender], “Agent already registered”);
// 可选:要求最低质押金,防止垃圾账号刷屏
// require(msg.value >= 0.01 ether, “Minimum stake required”);
AgentProfile memory newAgent = AgentProfile({
name: _name,
endpoint: _endpoint,
capabilities: _capabilities,
stakeAmount: msg.value, // 记录质押进来的 ETH
registerAt: block.timestamp,
isActive: true, // 默认注册即激活 (也可以设为false需审核)
walletAddr: msg.sender
});
agents[msg.sender] = newAgent;
isRegistered[msg.sender] = true;
agentList.push(msg.sender);
emit AgentRegistered(msg.sender, _name, msg.value);
}
/**
@notice Agent 更新自己的信息 (比如换了服务器IP,或者增加了新能力)
@dev 只有 Agent 自己能改自己的信息
*/
function updateMyself(
string calldata _newEndpoint,
string[] calldata _newCapabilities
) external {
require(isRegistered[msg.sender], “Not registered”);
require(agents[msg.sender].isActive, “Account banned”);
AgentProfile storage profile = agents[msg.sender];
profile.endpoint = _newEndpoint;
profile.capabilities = _newCapabilities;
emit AgentUpdated(msg.sender, _newEndpoint);
}
/**
@notice Agent 退出的逻辑 (提取质押金)
@dev 实际生产中通常需要一个“解锁期”,防止作恶后立即跑路
*/
function unregister() external {
require(isRegistered[msg.sender], “Not registered”);
// 简单示例:直接退款并删除状态
uint256 amount = agents[msg.sender].stakeAmount;
agents[msg.sender].isActive = false;
agents[msg.sender].stakeAmount = 0;
// 转账退回质押金
if (amount > 0) {
payable(msg.sender).transfer(amount);
}
}
// ==========================================
// 2. 平台管理接口 (Admin 调用)
// ==========================================
/**
- @notice 管理员修改 Agent 状态 (如发现作恶,紧急封禁)
*/
function setAgentStatus(address _agentAddr, bool _status) external onlyRole(MANAGER_ROLE) {
require(isRegistered[_agentAddr], “Agent not found”);
agents[_agentAddr].isActive = _status;
emit AgentStatusChanged(_agentAddr, _status);
}
/**
- @notice 扣除 Agent 质押金 (罚没机制)
- @dev 当 Arbiter 裁决 Agent 作恶时调用
*/
function slashAgent(address _agentAddr, uint256 _amount) external onlyRole(MANAGER_ROLE) {
require(agents[_agentAddr].stakeAmount >= _amount, “Insufficient stake”);
agents[_agentAddr].stakeAmount -= _amount;
// 罚没的钱可以转到国库地址
payable(msg.sender).transfer(_amount);
}
// ==========================================
// 3. 查询接口 (View)
// ==========================================
function getAgent(address _agentAddr) external view returns (AgentProfile memory) {
return agents[_agentAddr];
}
// 获取 Agent 总数
function getAgentCount() external view returns (uint256) {
return agentList.length;
}
}
流程说明:
Web2 注册 (Off-chain):
用户在你们的 Web 平台注册,点击“创建 Agent”。
平台后台为该 Agent 生成一个以太坊钱包(私钥 A),并分配 Web 登录密码。
关键点:平台将私钥 A 加密存储,或让用户下载 keystore.json 文件。
Driver 启动 (Local Environment):
用户下载 Java Driver 包,在配置文件里填入私钥 A 和 Web 平台给的配置。
Driver 启动。
Web3 注册 (On-chain):
Driver 启动时,自动调用合约的 isRegistered(myAddress)。
如果返回 false,Driver 调用 registerSelf(“MyAgent”, “http://1.2.3.4:8080“, [“txt2img”])。
这一步可能需要消耗少量的 Gas(ETH)。如果是你们分配的钱包,你们可能需要预先往钱包里转一点点 ETH 作为 Gas 费,或者使用 Meta-Transaction (元交易) 代付 Gas。
开始接单:
注册成功后,isActive 变为 true。
Driver 开始监听任务合约,准备抢单。
1.2.2.2. 任务类别工厂 (TaskTypeFactory)
作用:管理端用来“发任务类别”。
逻辑:当你在后台新增一个“文生视频”类别时,合约会自动部署一个新的 TaskSheet 合约实例。
contract TaskTypeFactory is AccessControl {
// 事件:通知 Java 引擎有新类别上线了
event TaskTypeCreated(string typeName, address taskSheetAddress);
struct TaskCategory {
string typeName; // 类别名 (如 “Text-to-Image”)
address taskContract; // 对应的具体的 TaskSheet 合约地址
uint256 defaultTimeout;// 该类任务默认超时时间 (如 30分钟)
uint256 basePrice; // 该类任务的基础单价
}
// 映射: 类别名 => 详情
mapping(string => TaskCategory) public categories;
string[] public categoryList; // 方便前端遍历展示
// 管理端接口:部署新任务板
function createCategory(string memory _typeName, uint256 _timeout) external onlyRole(ADMIN) {
// 部署一个新的 TaskSheet 实例
TaskSheet newSheet = new TaskSheet(_typeName, _timeout, msg.sender);
categories[_typeName] = TaskCategory({
typeName: _typeName,
taskContract: address(newSheet),
defaultTimeout: _timeout,
basePrice: 0
});
categoryList.push(_typeName);
emit TaskTypeCreated(_typeName, address(newSheet));
}
}
1.2.2.3. 具体任务表 (TaskSheet) —— 核心业务
作用:这是 Driver 抢单的战场。每个任务类别对应一个本合约的实例。
contract TaskSheet is AccessControl {
// 权限:只有拆解引擎(Engine)能发任务和验收
bytes32 public constant ENGINE_ROLE = keccak256(“ENGINE_ROLE”);
struct Task {
uint256 id; // 任务ID (自增)
string inputParams; // 任务参数 (JSON字符串 或 IPFS Hash)
// 举例: { “prompt”: “a cyberpunk cat”, “width”: 1024 }
string outputResult; // 结果 (OSS链接,初始为空)
TaskStatus status; // 状态 (PENDING/ASSIGNED/…)
address worker; // 抢到单的 Driver 地址
uint256 createdAt; // 创建时间
uint256 assignedAt; // 抢单时间 (用来计算超时)
uint256 completedAt; // 完成时间
uint256 price; // 该任务的定价
}
// 存储所有任务
mapping(uint256 => Task) public tasks;
uint256 public taskCounter;
// 辅助队列:为了让 Driver 快速找到 PENDING 的任务,不用遍历整个 mapping
// 实际生产中可能需要更复杂的数据结构,这里用简单的数组示意
uint256[] public pendingTaskIds;
// 初始化
constructor(string memory _name, uint256 _timeout, address _admin) {
_grantRole(DEFAULT_ADMIN_ROLE, _admin);
_grantRole(ENGINE_ROLE, _admin);
}
// ================= 引擎调用接口 =================
// 1. 发布任务
function createTask(string calldata _params, uint256 _price) external onlyRole(ENGINE_ROLE) {
taskCounter++;
tasks[taskCounter] = Task({
id: taskCounter,
inputParams: _params,
outputResult: “”,
status: TaskStatus.PENDING,
worker: address(0),
createdAt: block.timestamp,
assignedAt: 0,
completedAt: 0,
price: _price
});
pendingTaskIds.push(taskCounter);
emit TaskCreated(taskCounter, _params);
}
// 4. 验收结算 (Engine 更新 Task 表)
function finalizeTask(uint256 _taskId, bool _approved) external onlyRole(ENGINE_ROLE) {
Task storage t = tasks[_taskId];
require(t.status == TaskStatus.SUBMITTED, “Invalid status”);
if (_approved) {
t.status = TaskStatus.COMPLETED;
t.completedAt = block.timestamp;
// TODO: 触发 ERC20 转账逻辑
} else {
t.status = TaskStatus.PENDING; // 驳回,重新变为待领取
t.worker = address(0);
// 重新加入 pending 队列逻辑…
}
emit TaskFinalized(_taskId, _approved);
}
// ================= Driver 调用接口 =================
// 2. 抢单 (主动抢占)
function claimTask(uint256 _taskId) external {
// 检查 AgentRegistry 是否合规 (可以是跨合约调用,也可以依赖 Engine 只有发白名单 Driver)
Task storage t = tasks[_taskId];
require(t.status == TaskStatus.PENDING, “Task not available”);
t.status = TaskStatus.ASSIGNED;
t.worker = msg.sender;
t.assignedAt = block.timestamp;
// 从 pending 队列移除的逻辑 (略,需优化 gas)
emit TaskAssigned(_taskId, msg.sender);
}
// 3. 提交结果
function submitResult(uint256 _taskId, string calldata _ossUrl) external {
Task storage t = tasks[_taskId];
require(t.worker == msg.sender, “Not your task”);
require(t.status == TaskStatus.ASSIGNED, “Wrong status”);
t.outputResult = _ossUrl;
t.status = TaskStatus.SUBMITTED;
emit TaskResultSubmitted(_taskId, _ossUrl);
}
}
1.3. Agent Driver
初步设想是做一个cli,用户在我们的网站上注册完了之后登陆我们的cli,命令行直接在某个文件夹执行init吧我们的Driver给下载下来。我们的driver要直接匹配上面的所有能力,用户只需要申明一些配置文件和实现某些接口就可以运行。将driver的控制权给用户,用户初始化完成之后需要运行另一个cli命令,执行并且把状态啥的返回给他的web端,可以看到结果啥的。
1.3.1. 用户旅程 (The User Journey)
假设 CLI 命令为 talos。
1.3.1.1. 第一阶段:身份认证 (Auth)
用户在 Web 端注册后,获取一个 Access Token。
$ talos login
? Please paste your Access Token: ********************
Login successful! Welcome, User_9527.
后台逻辑:CLI 将 Token 存入 ~/.talos/credentials,后续用于拉取云端配置和鉴权。
1.3.1.2. 第二阶段:初始化工作区 (Init)
用户创建一个文件夹,准备开始接入网络。
$ mkdir my-sd-agent && cd my-sd-agent
$ talos init –template stable-diffusion
Downloading Talos Core Driver (v1.0.2)… [====================] 100%
Project initialized in ./my-sd-agent
后台逻辑:
下载核心 Jar 包(talos-core.jar)到本地 lib/ 目录。
生成标准目录结构和配置文件。
生成 Java/Python 接口模版代码。
1.3.1.3. 第三阶段:配置与实现 (Implement)
用户编辑配置文件,甚至编写代码来适配自己的硬件。
1.3.1.4. 第四阶段:注册与启动 (Run)
用户将自己的节点注册上链,并开始接单。
$ talos register –stake 0.1
Registering Agent on-chain… Success!
Wallet Address: 0xAbC…
$ talos start
Talos Driver v1.0.2 started.
Listening on TaskSheet Contract: 0x123…
Connected to Web Dashboard via WebSocket.
[INFO] Waiting for tasks…
1.3.2. 本地目录结构 (The Workspace)
执行 talos init 后,生成的目录结构应该类似 Maven/Gradle 项目,但更简化:
my-sd-agent/
├── talos.yaml # 核心配置文件 (申明能力、并发数、私钥路径)
├── .env # 环境变量 (API Key, 数据库密码)
├── lib/
│ └── talos-driver.jar # CLI自动下载的核心运行时 (闭源或开源)
├── plugins/ # 用户放第三方插件的地方
├── src/ # 用户实现接口的地方
│ └── MyImageGenerator.java
└── logs/ # 运行日志
1.3.3. 用户需要“实现”什么?(The Interface)
为了让用户拥有控制权,我们需要定义一套 SPI (Service Provider Interface)。用户只需要填空。
1.3.3.1. 配置文件 (talos.yaml)
这是最简单的接入方式,适合“配置型”用户。
name: “My-RTX4090-Node”
chain:
rpc_url: “https://eth-mainnet…”
registry_address: “0x…”
申明这个 Driver 具备的能力
capabilities:
- type: “text-to-image”
price_per_task: 10 # USDT
handler: “src.MyImageGenerator” # 指向下面的代码类
Web端监控配置
dashboard:
sync_interval: 5s
report_logs: true
1.3.3.2. 代码接口 (Java Interface)
这是给“开发者型”用户的。比如用户想用自己本地魔改过的 Stable Diffusion WebUI 接口,他需要写一个适配器。
用户收到的模版 (src/MyImageGenerator.java):
import com.talos.sdk.AgentInterface;
import com.talos.sdk.Task;
import com.talos.sdk.Result;
public class MyImageGenerator implements AgentInterface {
// 初始化:比如加载模型,检查显存
@Override
public void init(Config config) {
System.out.println(“Connecting to local SD WebUI…”);
}
// 核心逻辑:Driver 抢到单后会调这个方法
@Override
public Result execute(Task task) {
String prompt = task.getParams().get(“prompt”);
// 用户自己实现:调用本地 Python 脚本或 HTTP 接口
String imageUrl = HttpClient.post("http://localhost:7860/sdapi/v1/txt2img", prompt);
// 返回结果,Talos Driver 会负责上传 OSS 和上链
return Result.success(imageUrl);
}
}
1.3.4. talos start 背后的双线程机制
当用户运行 talos start 时,你的 Driver 会启动两个核心线程组,分别负责 Web3 赚钱 和 Web2 监控。
1.3.4.1. 线程组 A:Worker Thread (赚钱机器)
这是我们之前讨论的核心逻辑。
Listener: 监听链上 TaskSheet。
Executor: 调用用户写的 MyImageGenerator.java。
Submitter: 结果上传 OSS,哈希上链。
1.3.4.2. 线程组 B:Reporter Thread (Web 监控)
这是为了满足你提到的“返回给 Web 端,可以看到结果”。
Log Streamer: 劫持 Java 的 System.out 或 Slf4j,通过 WebSocket 实时推送到你们的中心化服务器。
State Syncer: 每 5 秒发送心跳包:“我还在活着,当前 CPU 占用 20%,刚刚抢到了 Task #105”。
Web 端效果:
用户在浏览器里打开 talos.com/dashboard,能看到一个类似“控制台”的界面,上面实时滚动着他本地 CLI 的日志,还能看到收益曲线。
1.4. 验收与分账
2. C端客户端
面向需求方(Requestor/User)的 Web 端,核心目标是“降低门槛,提供确定性”。用户不在乎背后是区块链还是 Java,只在乎任务能不能完成、要花多少钱、结果好不好。
2.1.1. 交互式工作流编辑器与模版市场 (Interactive Editor & Marketplace)
用户可能不知道如何构建复杂的 JSON 拓扑,你需要提供工具帮他生成。
拖拽式编辑器 (Node-Based Editor):
类似 ComfyUI 的前端实现(如使用 React Flow 或 X6)。
用户可以从左侧拖入“文生图节点”、“翻译节点”,连线组合,系统自动生成给后端的 JSON。
模版市场 (Workflow Store):
大多数用户只想“一键生成”。你需要提供预设模版库(如“Logo 设计流”、“小红书文案流”)。
社区共享:允许高级用户(Prompt Engineer)发布自己的工作流模版,其他用户使用时,发布者可以获得微量分润。
2.1.2. 实时状态流与中间件展示 (Live State & Intermediate Preview)
你提到了“动态展示”,这里需要做得更细致。
节点级进度条:
不仅仅是整个任务的进度,而是 DAG 图中每个节点的状态(排队中 -> 计算中 -> 上传中 -> 完成)。
高亮当前 Agent:当任务运行到“节点 A”时,UI 上显示:“正在由 Agent DeepSeek-01 执行…(信誉分 98)”。
中间结果预览 (Intermediate Outputs):
如果是一个 3 步的任务(草图 -> 线稿 -> 上色),用户不需要等最后一步。
当“草图节点”完成后,前端应当立即在节点旁边弹出一个缩略图,让用户有“实时看着它生成”的爽感。
2.1.3. 费用估算与预充值 (Cost Estimation & Pre-fund)
Web3 的痛点是“每次操作都要签名”和“Gas 费波动”。
执行前估价:
在用户点击“运行”之前,后端根据当前任务链的复杂度、涉及的 Agent 类型单价、链上 Gas 费,计算出一个 “预估总价 (Estimated Cost)”。
账户余额模式 (Deposit Model):
极差体验:每发一个 Prompt 都要弹 MetaMask 签名付 Gas。
优化体验:用户先充值 100 USDT 到平台的智能合约账户(类似交易所充值)。发任务时,后端直接扣除合约内的余额(通过 EIP-712 签名鉴权),实现无感支付。
2.1.4. 结果画廊与资产管理 (Gallery & Asset Mgmt)
这是用户的“战利品仓库”。
多媒体画廊:
瀑布流展示用户历史生成的所有图片/视频/文本。
支持按任务类型、时间、Prompt 关键词搜索。
元数据追溯:
点击一张图片,能翻转看到它的“出生证明”:使用的 Prompt、Seed、模型版本、执行 Agent 的签名哈希、链上交易 ID。这是 Web3 AI 的核心价值——可验证性。
一键 Fork:
看到历史记录里一张效果很好的图,点击“Remix / Fork”,自动把当时的参数和工作流填回编辑器,方便微调重跑。
2.1.5. 评价与仲裁系统 (Rating & Dispute)
这是你提到的“可靠性分析”的数据来源。
RLHF 反馈入口:
任务完成后,让用户点“赞/踩”。
如果是“踩”,弹出选项:是“结果不符合 Prompt”还是“画质太差”?这些数据回传给后端,用于降低该 Agent 的信誉分,优化路由算法。
申诉通道:
如果 Agent 提交了一张纯黑的图骗钱,用户需要有入口点击“申请退款”。
这会触发链上的仲裁流程(Arbiter),或者先由平台客服介入处理。
2.1.6. 需求方 Web 端架构总结
模块
核心功能
技术关键词
创作台
拖拽编辑、模版选择、参数配置
React Flow, JSON Schema Form
监控室
DAG 实时渲染、中间结果预览、Agent 信息展示
WebSocket, Server-Sent Events (SSE)
钱包/账户
SIWE 登录、预充值、消费明细、Gas 估算
RainbowKit, EIP-712, Paymaster
资产库
历史记录、元数据查看、下载/导出
IPFS/OSS, Infinite Scroll
反馈中心
评分、举报、申诉
Rating System, Customer Support
3. Agent提供者客户端
这个web后端是面向提供agent的人群,他需要在我们的平台上注册他的agent,然后我们给他返回一些key,方便他在调用我们的driver时可以填入然后开启接单。
3.1.1. 凭证与安全管理中心 (Credential & Security)
API Key 生命周期管理:
多 Key 支持:允许一个账号生成多个 Driver Key(例如他有 10 台服务器,每台用不同的 Key,方便区分监控)。
权限控制:设置 Key 的权限(只读、只接单、可提现)。
一键重置/吊销:如果 Driver 所在的服务器被黑了,用户必须能在 Web 后端一键吊销 Key,防止私钥或额度被盗用。
钱包绑定与验证:
强制绑定 Web3 钱包(MetaMask 等)。后端需记录“Web2 账号 ID <-> 链上钱包地址”的映射关系,确保提现时只能提到绑定的钱包。
3.1.2. 节点监控仪表盘 (Node Monitoring Dashboard)
用户最关心的就是:“我的机器还在跑吗?有没有死机?”
实时心跳与状态:
展示所有连接的 Driver 状态(Online/Offline/Busy)。
告警系统:如果 Driver 连续 5 分钟未发送心跳(掉线),后端需通过邮件或 Webhook(钉钉/Telegram)通知用户。
资源遥测 (Telemetry):
从 Driver 上报的数据中通过 WebSocket 展示实时的 CPU、内存、显存(VRAM)占用率。这对于 AI 任务至关重要,防止爆显存。
实时日志流:
在网页上直接查看 CLI 的运行日志(stdout/stderr),方便远程排查报错,而不需要 SSH 登到服务器上去看。
3.1.3. 收益与财务分析 (Earnings & Finance)
这是驱动用户接入的核心动力。用户需要算账。
收益可视化:
展示“今日预估收益”、“历史总收益”、“待领取收益”。
提供图表:收益趋势图(按小时/天)。
Gas 费分析:
关键痛点:Driver 抢单是需要付 Gas 的。
后端需要帮用户计算 净利润 = 任务奖励 (Token) - 抢单 Gas (ETH)。如果 Gas 费过高导致亏本,要标红提醒用户优化策略。
质押管理 (Staking):
显示当前的质押金额、信誉分(Reputation Score)。
提供“追加质押”或“申请解锁”的向导指引。
3.1.4. 任务历史与审计 (Task History & Audit)
用户需要知道自己的机器到底干了什么活。
任务流水:
列表展示所有抢到的任务:TaskID | 类型 | 耗时 | 状态(成功/失败) | 结果链接。
失败原因分析:
如果任务失败(Failed),后端要解析 Driver 上报的错误码。是“网络超时”、“显存不足”还是“Prompt 不合法”?给用户提供优化建议。
OSS 资源管理:
用户可以查看自己生成的图片/文本的历史存档(基于 OSS 链接),并可以手动清理旧数据以节省 OSS 成本(如果用的是用户自己的 OSS)。
3.1.5. 策略配置与优化 (Configuration & Optimization)
让用户在 Web 端就能控制 CLI 的行为,而不是每次都去改服务器上的 yaml 文件。
远程配置下发:
用户在网页上修改“最大并发数”、“最低接单价格”、“任务类型偏好(只接文生图)”。
后端将配置推送到 CLI,Driver 实时热更新。
自动化策略:
定时休眠:设置“夜间电费便宜时全速跑,白天电费贵时暂停”。
Gas 保护:设置“当 Gas Price > 50 Gwei 时自动暂停抢单”。
3.1.6. 开发者中心 (Developer Hub)
针对那些具备开发能力、想要自定义 Driver 逻辑的高级用户。
SDK 与文档下载:提供 Java/Python SDK 包,以及详细的接入文档。
Debug 工具:
任务重放 (Replay):允许用户在本地模拟执行某个链上历史任务,用于调试自己的算法模型。
镜像/模版市场:
官方提供预配置好的 Docker 镜像(如集成了 Stable Diffusion WebUI 的镜像),用户一键拉取即可开工。
3.1.7. 总结:Agent 提供者的用户旅程
回到你的 Web 后端,Agent 提供者的操作流应该是这样的:
注册/登录 -> 2. 绑定钱包 -> 3. 创建 Agent (获取 Key) -> 4. 配置 CLI (填入 Key) -> 5. 启动 Driver -> 6. 回到 Web 端看仪表盘 (监控赚钱)。
所以,这个 Web 后端就是他们的 “矿机管理后台”。
- 小二管理端。


 图22.png
图22.png