网易牛马日志-完结篇
文章目录
过年以后回来做的东西太杂了,想到哪说哪吧。
需求12:出海项目搜索功能
这个得包装了,好不容易一个可能的高并发C端接口,但是实际上做的很简单。
搜索V1:实际做的
数据库直接like就完了,纯纯没有一丝的技术含量。
搜索V2:包装。。。未完待续
需求13:全球搜数据工程产品图片爬取
这部分只做了前段部分,用jsoup去解析标签,再getDocumentByClass去找url,图片名称和信息。
这里也不清楚class会不会随着编译改变,但是测试下来确实是可以的。
1 | public ExtraResultDTO doExtra(String domain){ |
需求14:全球搜数据工程公司Logo爬取
比较有挑战性的一整个链路,问题在于es里面logo字段并不是索引,所以不能用exist来查询。主要思路是查询线上有域名的公司,过滤掉有logo字段的,将无logo字段但是有域名的公司通过kafka消费到本地,然后通过爬虫将图片下载下来。
前处理链路:
链路:
- 猛犸抽取线上es到hive,这一段全量数据写入hive,大概2600万。
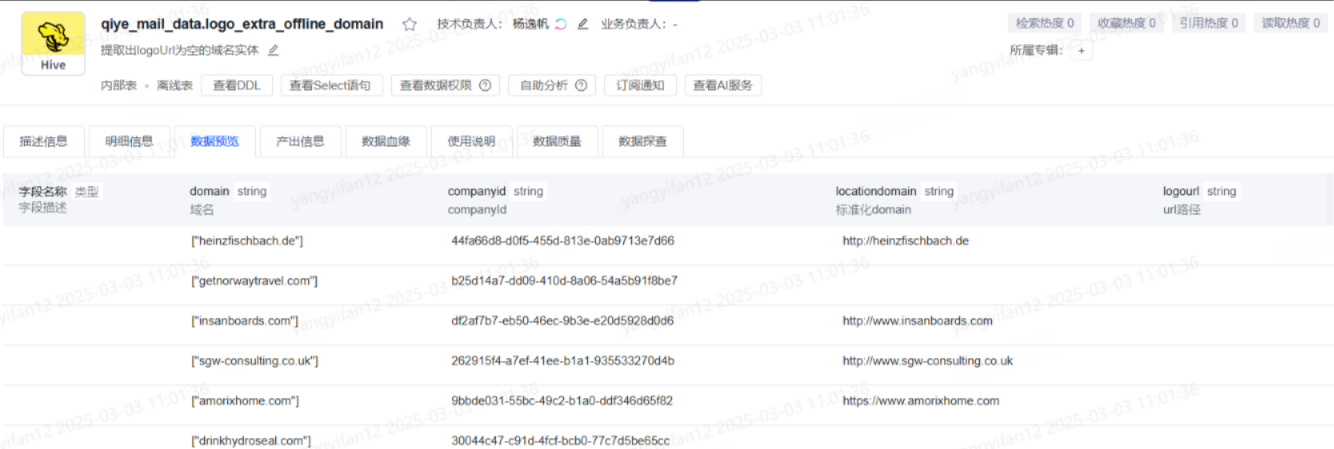
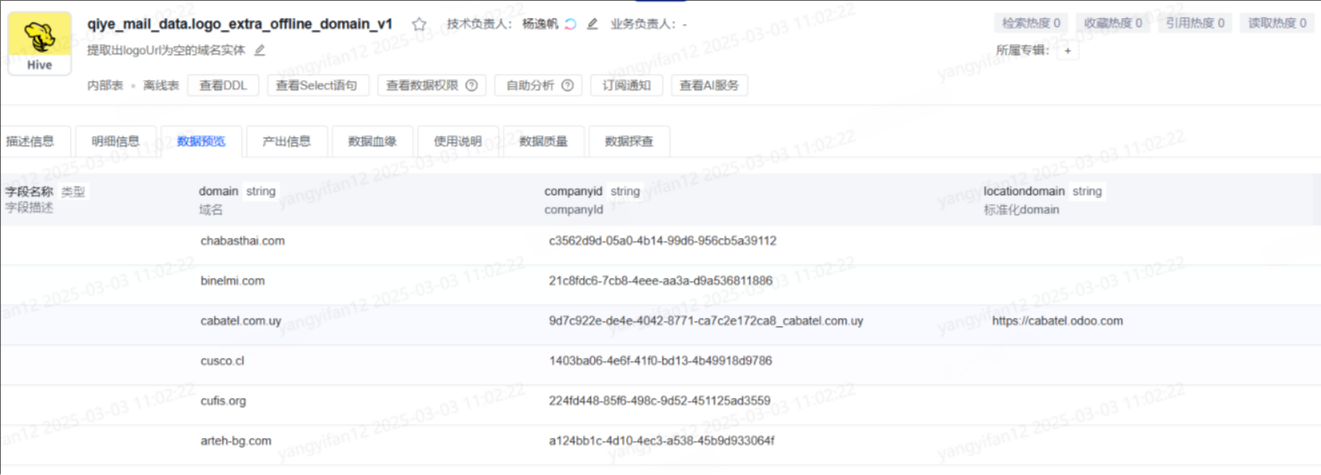
- 然后hive ->hive,通过sql来过滤掉有logo的公司域名,此外由于抽取的域名domain是从一个list里面来的,在变成字符串后有”[“和”]“,需要过滤,最后得到数据量大概1600万。
1 | insert |
- 最后猛犸任务hive->kafka,测试环境集群做消费,这才正式进入logo图片提取的链路。
责任链模式进行公司Logo爬取
首先是三种找Logo的方法,一般来说Logo都会放在浏览器的ico上,相关链接在csdn:
- 通过google某个api拿,这种成功率最高,但是会返回默认图片,后续需要校验md5来过滤。
- 直接在网站域名后面拼接/favicon.ico,成功率不高,因为小公司的网页并不一定有这么规范,其次是可能会返回404的html页面,也会有默认的ico文件,所以要写一个方法过滤html和默认的md5.
- 爬虫解析,拿到domain的源码,再去解析里面的,然后通过正则表达式去匹配icon,成功率不高,属于是最后的底牌了。
另外这里有的都是domain,意思是没有http和https的,所以都需要进行尝试,综上所述,一共得走6个链路,哪个成功了哪个就返回,很适合责任链模式。
1 | // 责任链执行 |
上传到nos
调洋总的接口就完事了,然后将这个链接保存进es,良总那里会有一个同步链路将触发版本更新的数据同步到线上。最终的效果就是测试集群在消费数据,将爬取的logo的nosurl保存进es并更新版本号,最后用同步链路更新到线上。
需求15:全球搜应用工程ai推荐理由总结
比较简单,就是多线程调用大模型api,由于需要时效性,deepseek要输出思维链所以时效性很差,不适合用在业务里面,所以用gpt。其次开一个线程池来优化并发请求,此外就是prompt优化,很简单的一个需求。
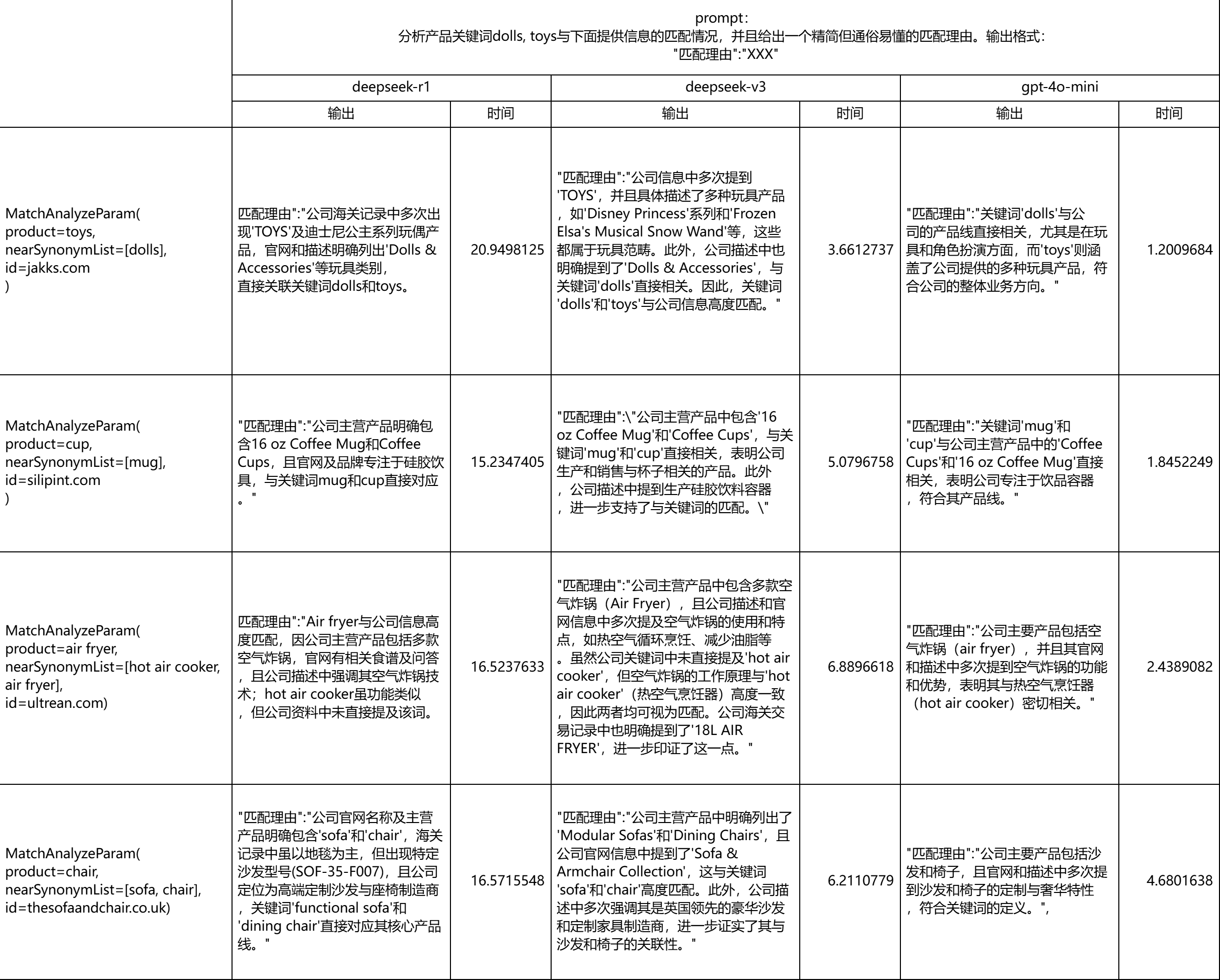
关于提示词,mentor的意思是尽量可读性高,产品词输出中文,看的会比较丝滑,但是在第一版的提示词里面海关数据基本没怎么用,后续就变为:
1 | prompt: |
- 线程池:
1
2
3private static final ThreadFactory MATCH_ANALYZE_LLM_THREAD_FACTORY = new ThreadFactoryBuilder().setNameFormat("MatchAnalyzeService-llm-pool-%d").build();
private static final ExecutorService LLM_REQUEST_EXECUTOR = new ThreadPoolExecutor(20,
40, 60 * 5L, TimeUnit.SECONDS, new LinkedBlockingDeque<>(3000), MATCH_ANALYZE_LLM_THREAD_FACTORY, new ThreadPoolExecutor.CallerRunsPolicy()); - prompt:
1
2
3private static final String BASE_PROMPT = "根据提供的信息,总结公司的主营产品、海关交易产品等信息,并判断分析与关键词{0}的相关性,给出最终的匹配理由。输出格式:\n" +
"\"匹配理由\":\"XXX\"\n" +
"以下是公司信息:\n"; - 动态组装和展示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
public MatchAnalyzeResultDTO getMatchAnalyze(MatchAnalyzeParam globalSearchParam) {
//参数校验,id非空
if (globalSearchParam == null || StringUtils.isEmpty(globalSearchParam.getId())){
return new MatchAnalyzeResultDTO();
}
CompanySearchBO companySearchBO = companySearchService.queryById(globalSearchParam.getId(),
new String[]{"customsItems", //海关交易数据
"htagItems", //公司官网
"overviewDescription", //公司描述
"detail.productList.name", //产品图片描述
"keywords", //公司关键词
"detail.mainProducts", //公司主营产品
"brandNames" //公司品牌信息
},
null);
//索引不存在,返回空
if (companySearchBO == null){
return new MatchAnalyzeResultDTO();
}
//合并搜索词和扩展词
List<String> nearSynonymList = globalSearchParam.getNearSynonymList();
nearSynonymList.add(globalSearchParam.getProduct());
String trimNearSynonymList = nearSynonymList.toString().replaceAll("\\[|\\]", "");
StringBuilder promptStringBuilder = new StringBuilder(MessageFormat.format(BASE_PROMPT,trimNearSynonymList));
if (companySearchBO.getCustomsItems() != null && !companySearchBO.getCustomsItems().isEmpty()){
//裁剪为10个以内,避免token超出
List<String> subCustomsItemsList = companySearchBO.getCustomsItems().subList(0, Math.min(companySearchBO.getCustomsItems().size(), LIST_LENGTH_LIMIT));
promptStringBuilder.append("公司的海关交易记录:").append(subCustomsItemsList).append("\n");
}
if (companySearchBO.getHtagItems() != null && !companySearchBO.getHtagItems().isEmpty()){
//裁剪为10个以内,避免token超出
List<String> subHtagItemsList = companySearchBO.getHtagItems().subList(0, Math.min(companySearchBO.getHtagItems().size(), LIST_LENGTH_LIMIT));
promptStringBuilder.append("公司的官网信息:").append(subHtagItemsList).append("\n");
}
if (StringUtils.isNotEmpty(companySearchBO.getOverviewDescription())){
promptStringBuilder.append("公司描述:").append(companySearchBO.getOverviewDescription()).append("\n");
}
//产品图片描述处理
if (companySearchBO.getDetail() != null && companySearchBO.getDetail().getProductList() != null && !companySearchBO.getDetail().getProductList().isEmpty()){
List<ProductVO> productList = companySearchBO.getDetail().getProductList().subList(0, Math.min(companySearchBO.getDetail().getProductList().size(), LIST_LENGTH_LIMIT));
//映射为name
List<String> productListName = productList.stream().map(ProductVO::getName).collect(Collectors.toList());
promptStringBuilder.append("产品图片描述:").append(productListName).append("\n");
}
if (companySearchBO.getKeywords() != null && !companySearchBO.getKeywords().isEmpty()){
promptStringBuilder.append("公司关键词:").append(companySearchBO.getKeywords()).append("\n");
}
//公司主营产品处理
if (companySearchBO.getDetail() != null && companySearchBO.getDetail().getMainProducts() != null && !companySearchBO.getDetail().getMainProducts().isEmpty()){
Set<String> mainProducts = companySearchBO.getDetail().getMainProducts();
List<String> subMainProductsList = new ArrayList<>(mainProducts).subList(0, Math.min(mainProducts.size(), LIST_LENGTH_LIMIT));
promptStringBuilder.append("公司主营产品:").append(subMainProductsList).append("\n");
}
if (companySearchBO.getBrandNames() != null && !companySearchBO.getBrandNames().isEmpty()){
List<String> subBrandNamesList = companySearchBO.getBrandNames().subList(0, Math.min(companySearchBO.getBrandNames().size(), LIST_LENGTH_LIMIT));
promptStringBuilder.append("公司品牌信息:").append(subBrandNamesList).append("\n");
}
//拼接的最终prompt
String finalPrompt = promptStringBuilder.toString();
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(
() -> gptGrpcWrapper.gptRequest("6888072","583828445","yangyifan12@corp.netease.com",finalPrompt, GPTModelVersionEnum.GPT_4O_MINI.getVersion()), LLM_REQUEST_EXECUTOR);
String result = (String) FutureResultUtil.getResult("match-analyze-llm-future",future2,120, TimeUnit.SECONDS);
return new MatchAnalyzeResultDTO(result);
}