网易KM社区分享-快速搭建基于RAG的热点 AI搜索引擎
文章目录
大模型的出现带来了新的技术革新,它强大的对话,分析,生成能力可以应用在音乐的很多方面。我们希望借助大模型的能力, 实现对站内外音乐热点词条内容进行抽取,分析,总结,推荐。 本文将系统的介绍我们如何基于RAG 搭建一个带前端页面的 热点AI检索功能agent
体验地址:http://llm-zq.jupyter.panshi-gy.netease.com/
1.背景
大模型的出现带来了新的技术革新,它强大的对话,分析,生成能力可以应用在音乐的很多方面。我们希望借助大模型的能力, 实现对站内外音乐热点词条内容进行抽取,分析,总结,推荐。 但是:
- 大模型对于时事热点等,幻觉能力严重,而RAG(检索增强生成)可以解决这个问题。
- 很多都离不开外部的依赖接口,无法做到完全的offline, 且当token量大之后,费用也很大, 但其实开源的很多模型如LLAMA, QWEN等都已经有非常不错的能力。而且近期流行的ollama框架, 也让个人PC也都能支持大模型生成。
- 我们希望借助开源的能力,来快速搭建一个不依赖外部接口的AI检索引擎来为我们服务, 也避免了隐私泄露的风险。
它的主要特点:
- 不依赖外部接口, 离线实现LLM生成, 检索,embedding等能力。
- 基于互联网结果进行RAG,解决模型生成幻觉的问题,尤其可以支持对于近期热点知识的总结。
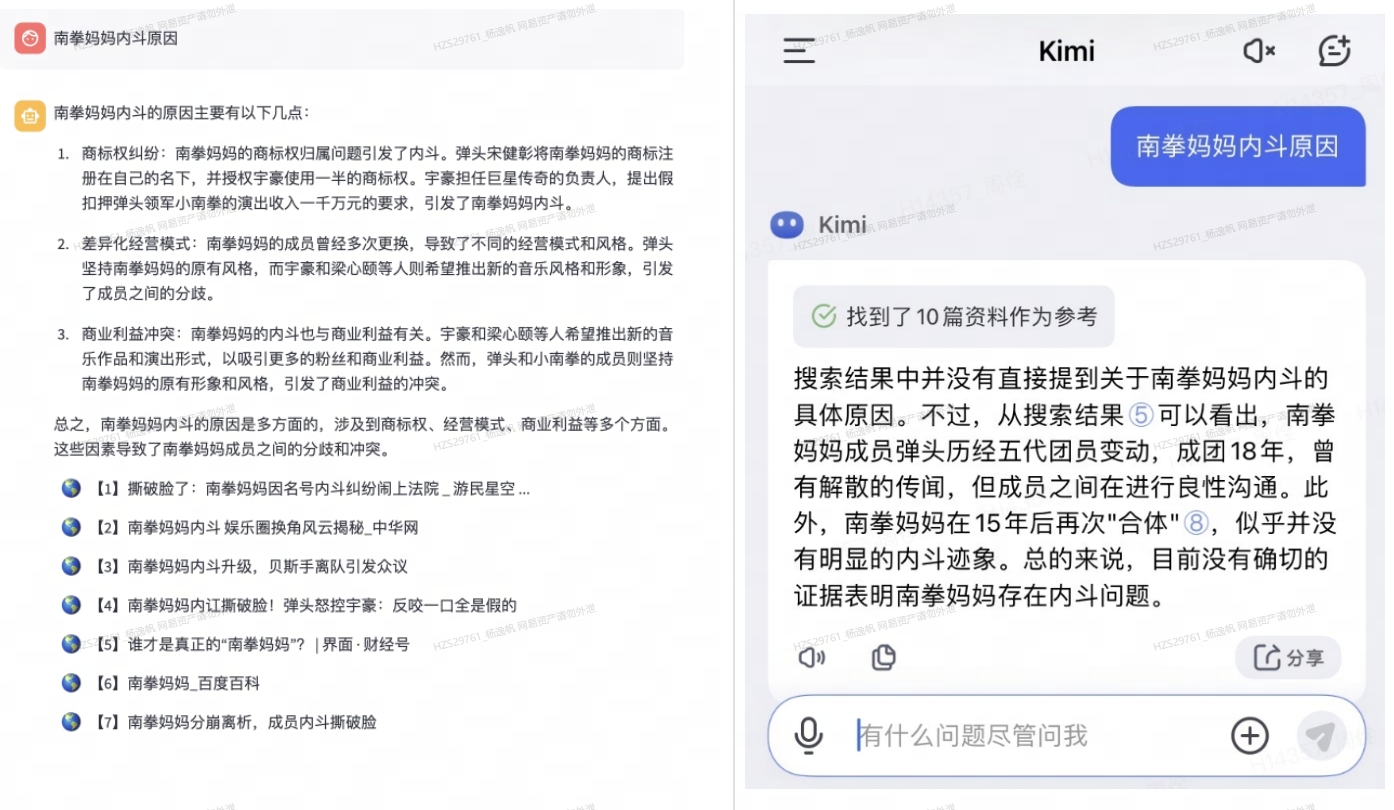
本文主要介绍开发这个agent的框架,一些技术细节和思路,希望给大家带来一点LLM 开发的收获。效果图如下,左边是我们的agent, 输入问题描述,系统即可自动调用搜索引擎并爬取互联网的内容,并通过大模型分析总结返回给我们问题的结果。在某些情况下,甚至比KIMI的效果还要好。
2.框架
总体框架如下图所示,主要包括3个子模块:
- (1) 检索爬取服务:根据用户搜索的热点关键词,调用自建的searxng 匿名检索服务系统, 获取top的互联网搜索引擎结果,并爬取相关网址全文内容。
- (2) 文档召回服务:对爬取的全文内容切块,进行向量化,同时对query也进行向量化,计算query和文档的相关性,并进行排序选取top的文档切块
- (3) 大模型生成服务。离线部署好大模型,输入相关文档和配置的prompt, 生成相关的检索答案汇总,并通过部署的streamlit前端服务返回给用户。
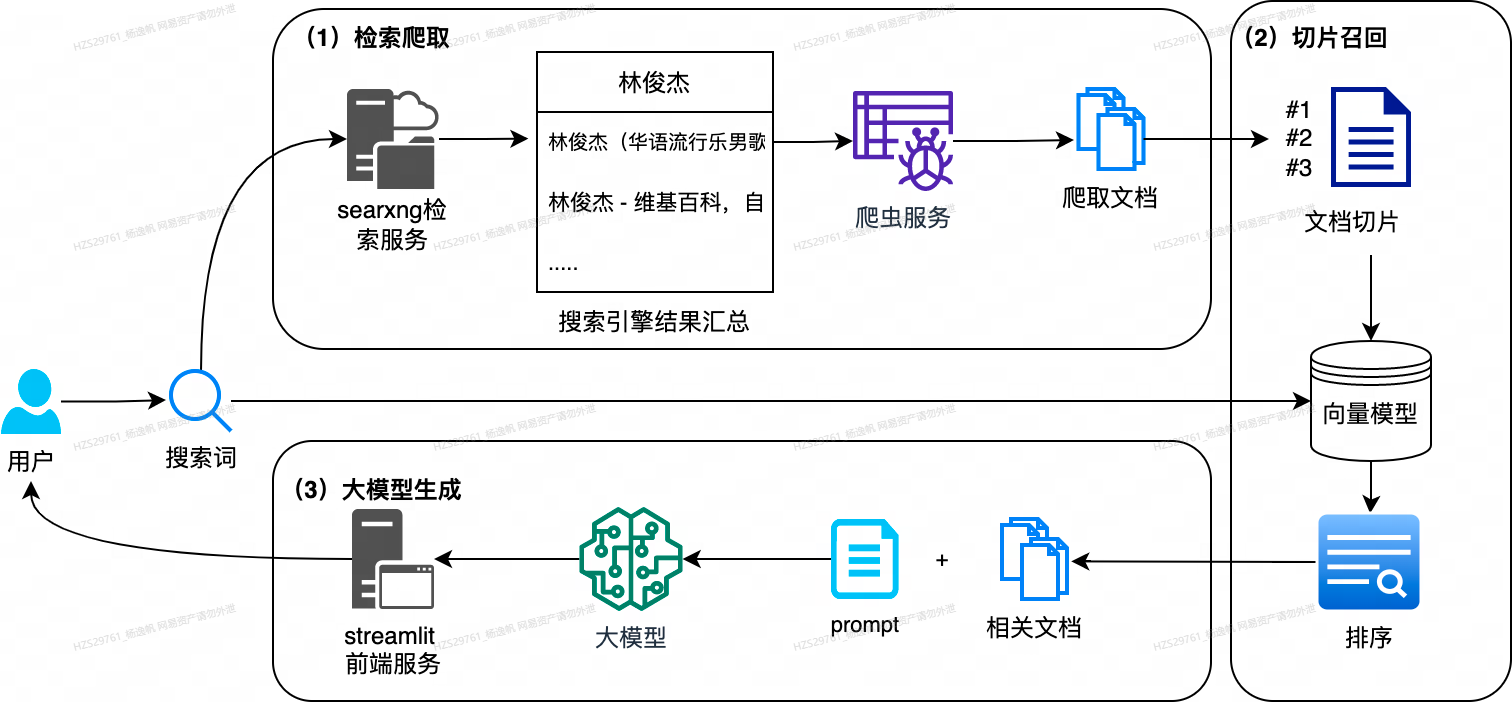
3个模块通过langchain框架进行串联起来工作,api接口都采用fastapi进行封装, 前端展示用streamlit进行交互开发。
3. 实现
基于基本的框架思路,我们前期调研了发现github已有类似的相关项目,在这些项目的基础上,我们做了一些优化。
LLocalSarch:https://github.com/nilsherzig/LLocalSearch
LangChain-SearXNG: https://github.com/ptonlix/LangChain-SearXNG
3.1 检索爬取服务
检索爬取服务主要有两个模块。searxng检索服务 和爬虫服务
3.1.1 searxng检索服务
SearXNG 是一个免费的互联网元搜索引擎,它聚合了来自各种搜索服务(如 google, duckduckgo等)和数据库(如wiki)的结果,但摆脱了隐私追踪。
当然,你也可以采用商业的搜索api 接口,比如google的Serper API , bing的Bing Web Search API,但这不是我们的目的,我们是希望搭建一个完全没有外部依赖的检索服务。
请注意,搭建searxng检索需要一台非大陆的VPS,并配有ipv4地址,如果嫌麻烦,可以用公共的searxng, 但是会有限制,地址:https://searx.space(需要FQ)
以下是搭建教程:
- 第一步:安装docker, docker-copose
docker安装:https://yeasy.gitbook.io/docker_practice/install/debian
docker-copose安装:https://yeasy.gitbook.io/docker_practice/compose/install
- 第二步:拉取searxng 镜像, 修改配置
修改项目docker配置
1 | # 拉取代码 |
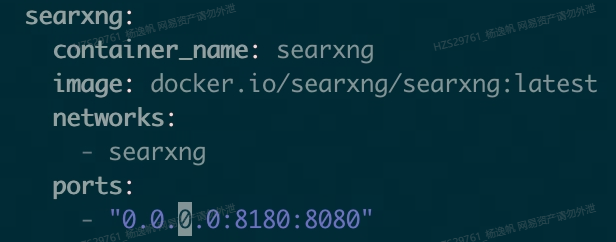
修改searxng主服务配置
1 | sed -i "s|ultrasecretkey|$(openssl rand -hex 32)|g" searxng-docker/searxng/settings.yml # 生成一个密钥 |
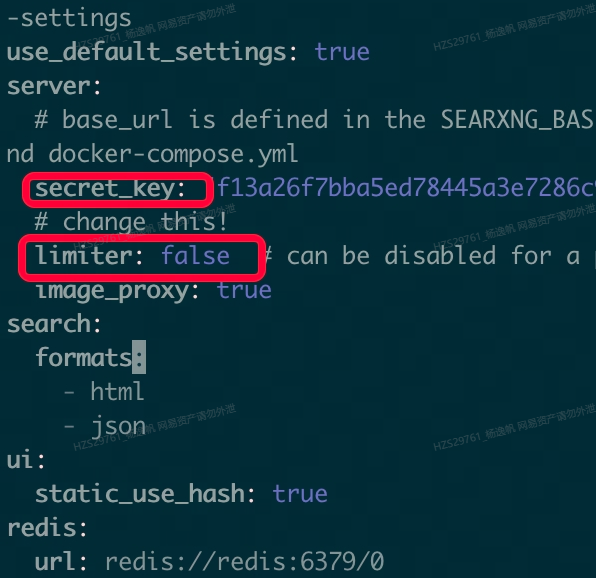
3.第三步:启动compose 服务组
1 | cd searxng-docker |
- 第四步:关闭端口防火墙并验证,如果没有防火墙则不需要这一步
1 | ufw allow 8180 |
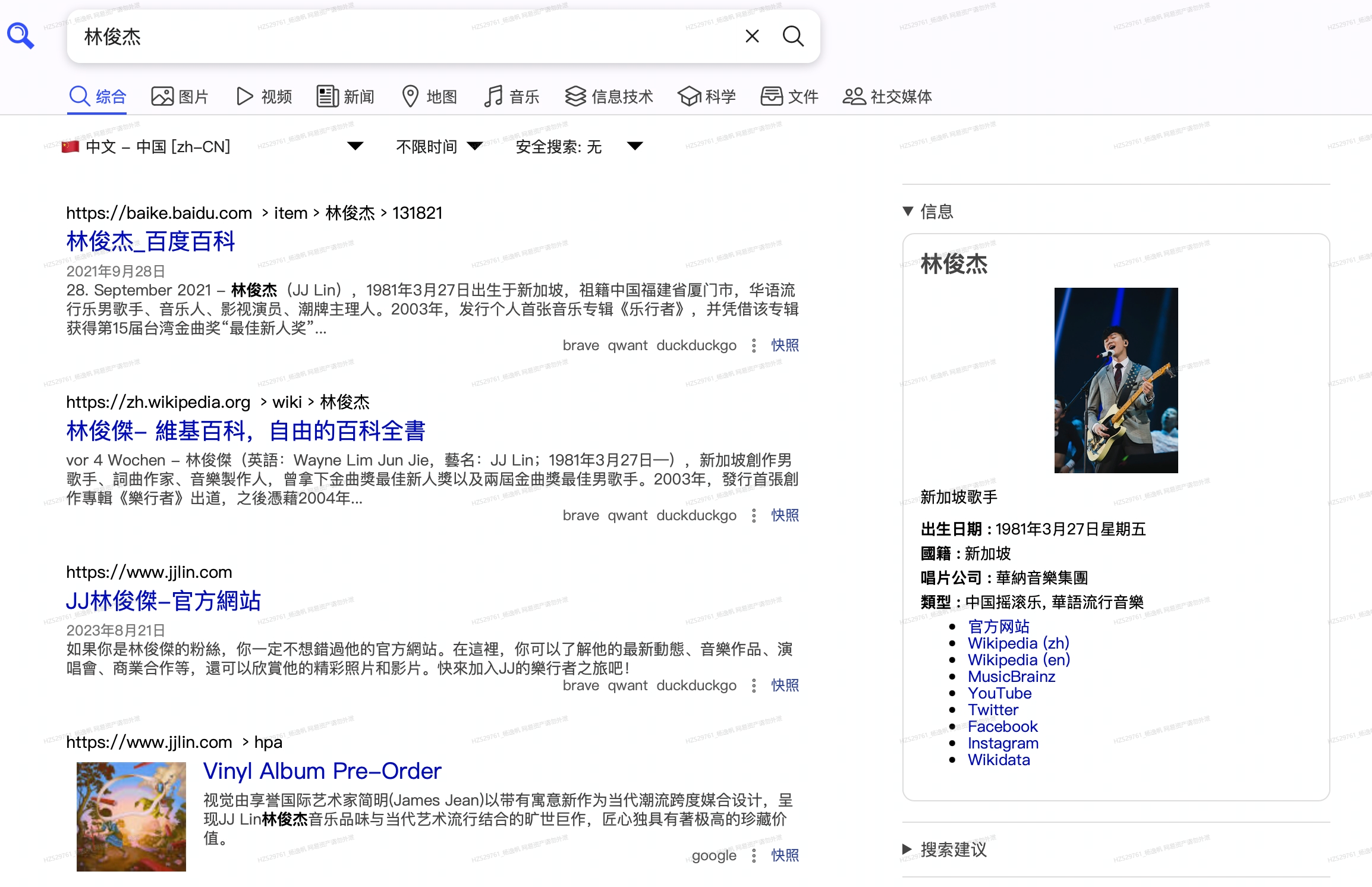
最后浏览器打开ip:8180,即可看到自己搭建的searxng页面并进行检索了,是不是很酷😎,没有任何广告,页面非常干净。
3.1.2 爬虫服务
单独searxng的结果信息量比较小,而对于LLM来说,丰富的信息意味着更准确的结果。 所以针对搜索引擎给出的相关网页,我们可以采用爬虫爬取top网页结果。 所幸,langchain(一个帮助在应用程序中使用大型语言模型的编程框架) 里就包含了相应的网页爬取模块,和文本解析模块。
1 | # langchain 调用searxng示例, 获取top结果 |
1 | # langchain 爬取示例 |
这里面在实践中存在几个主要问题:
- searxng的top结果中可能存在无法访问的(大陆),比如wiki 等,需要额外处理过滤。 这里我采用的是pac方式。过滤不能访问的网址
1 | # wget https://raw.githubusercontent.com/petronny/gfwlist2pac/master/gfwlist.pac |
- 可能存在超时的问题,有些网站链接速度非常慢,原本的langchain 爬取模块不支持超时,需要自己在外面额外封装一层超时控制。或者采用httpx的包进行批量爬取。
1 | import httpx |
- 爬取的结果如果是动态加载的内容,目前无法爬取。 比如 B站视频下的评论, 知乎的答案等。这种需要针对特定网站, 用自动化测试工具,比如Selenium 或者playwright. 这个待后续优化。
3.2 切块召回服务
这一步,其实主要对应RAG里R即retrieval, 召回。因为获取的top网址文本内容量比较大,一般单个网页的文本都接近5k token, 像百度知道这种以文本内容为主的基本都超过8k长度,多个网页内容直接丢给大模型解析,是个不太现实的任务,虽然现在有学者提出超长上下文的大模型(Long Context LLM)正在慢慢取代RAG, 但目前来说rag还是最优解。
召回过程是分为 切块,向量化,排序
3.2.1 切块
所有的文档进行chunk, 即切块, 比如以512个 token 作为一个chunk。这里面有几个问题:
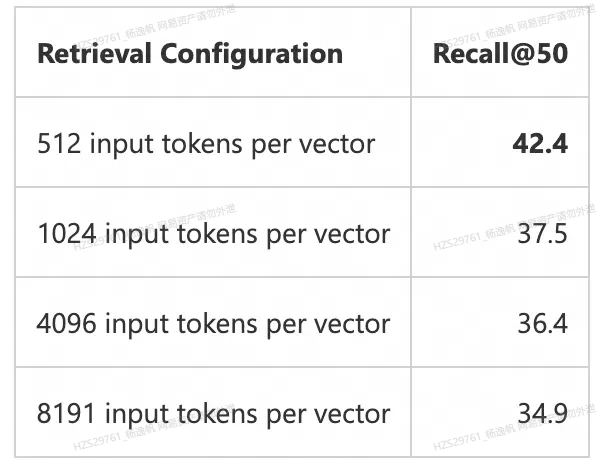
- 如何确定最佳块大小?
这个目前没有定论,主要还是取决于应用场景,具体可以参考微软[1]的建议并自行进行测试:
- 分割策略?
为了得到更好的结果,我们可以重叠相邻的块。来自微软分析的分块策略比较,显示512 tokens分块和25%的重叠是比较好的分块策略。 当然也要考虑embedding的模型
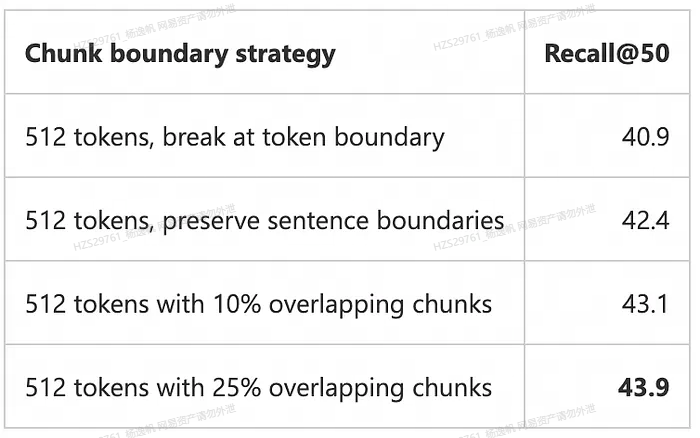
实际使用下来,应用于网页文本分块召回的比较好的参数, chunk=500,overlap=100, 向量模型采用BCE。
3.2.2 向量化
切块之后第二步就是对文档和query都进行向量化,并计算 query和 文档之间的相似度,再设定过滤的阈值,得到最终我们需要的文档片段。那么,向量模型该如何选取?
一般的商业大模型服务都自带embedding接口,比如openai的 v1/embedding, 这种需要api_key, 显然不是我们的目标。开源模型效果对比,可以参考,huggingface 的embedding竞技场:https://huggingface.co/spaces/mteb/leaderboard ,但是里面不是所有模型都有打分,下面是一些主流的embedding模型:
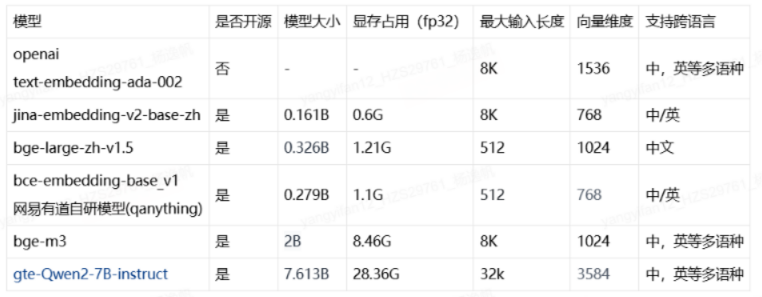
开源模型挑选可以从几个方面入手:
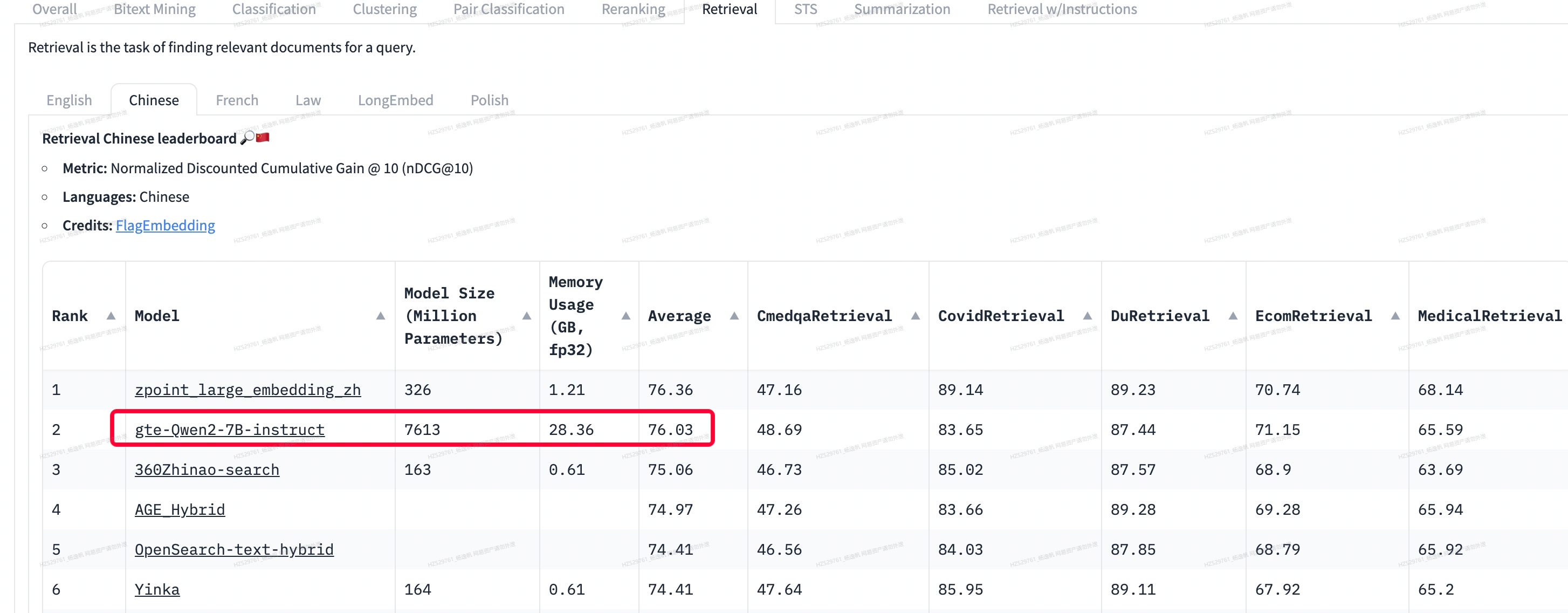
① 硬件性能。 因为单次用户请求,涉及很多切块文档,所以需要考虑机器性能和模型速度,其实很多常见的大模型做embedding效果也很好,但它不是主流因为效率很低,我们在mteb 评测榜单上可以看到 qwen2的检索效果非常好,但是模型太大很难应用。 尤其我们的任务都是实时算,并不存储向量,所以需要模型不太大。
② 向量维度。向量维度会影响到 存储以及检索耗时,对于常见的检索任务,是对知识库的内容预先算好相应的向量,并存储进向量数据库。 用户检索时,对检索词向量化,再通过近邻检索算法检索最相关的top结果。当数据量显著大时,向量维度越大,检索耗时越明显。我们的任务里不存储向量,所以这块也不需要考虑。
③ 最大输入长度。 指模型处理输入的最大token长度,这个和我们前面提到的分块大小息息相关,因为如果分块大小超过最大长度,则超过的部分会被向量模型丢弃,导致信息损失。
④ 支持语言。大部分开源向量模型只支持单一或者有限的文本语言,在需要多语言需求的场景可能不合适。需要注意的是,不支持多语言,不代表其他语言就不能向量化,而是缺乏跨语言匹配的能力。 比如[ ‘How is the weather today?’, ‘今天天气怎么样?’] 在单一语言里相似度可能很低,而对于多语言,则匹配度较高。一般来说,如果只是针对特定语言,选择单一语言模型即可,评分高的混合语言模型不一定比单一语言模型效果好。 由于网页内容繁杂,我们倾向于选择多语言模型
⑤ 领域表现。通用 Embedding 模型在特定垂直领域(如医学、法律和金融等)可能不如专用模型有效。这些领域通常需要专门训练 Embedding 模型来捕捉特定的专业术语和语境。为特定业务需求优化的 Embedding 模型能够显著提升检索和生成的质量。 网页内容匹配通常不需要考虑领域表现。
基于上面的维度,我们选择了中英双语的 bce-embedding-base_v1模型。
3.2.3 排序
顺便再聊一下,关于RAG中的召回,目前主流的做法是两个阶段。第一阶段query和文档向量化,检索框架采用faiss, 或者milvus 这种向量查询数据库。 第一阶段存在两个问题:
1、当doc数据量大的时候,检索算法都是近似的, 不是挨个遍历计算,会有损。除非用暴力挨个计算cos, 但这个不现实。(在本任务里是可以的,因为文档量很小)
2、embedding本来就是对于信息的压缩,对原始文本信息是有丢失的。
那么对于这些缺点,有办法优化吗? 答案是有的,即第二阶段rerank模型精排。 rerank模型输入query和doc对文本,而不是emebdding, 信息无损。 2阶段检索详情可以参考QAnything给出的示意图, 很清楚。
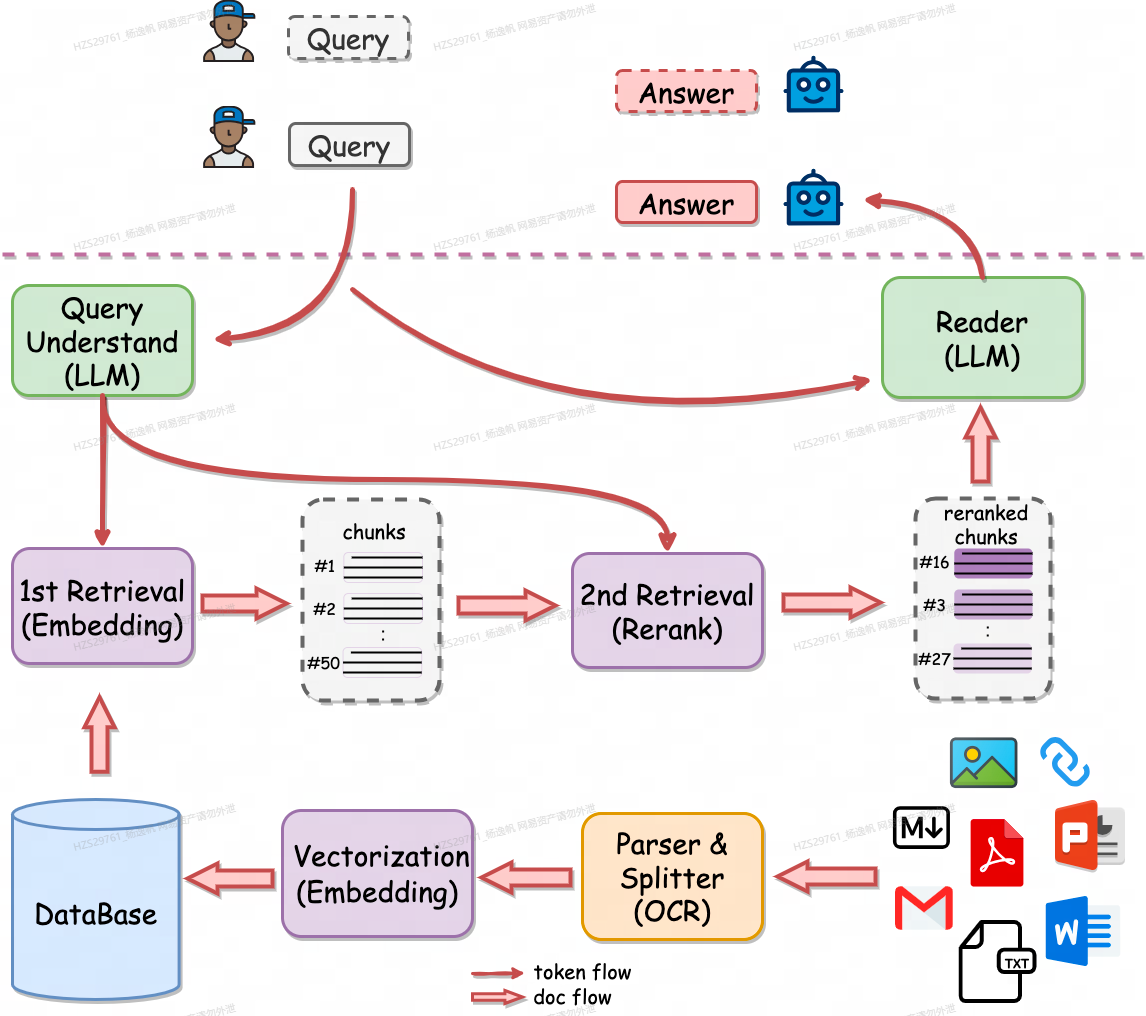
在加入二阶段rerank之后,BCE的效果, top10命中率由85.91%提升到93.46%,非常明显。同时可以看到,采用hybird, 即bm25和embedding召回,再经过rerank可以达到最好的效果96.36%。
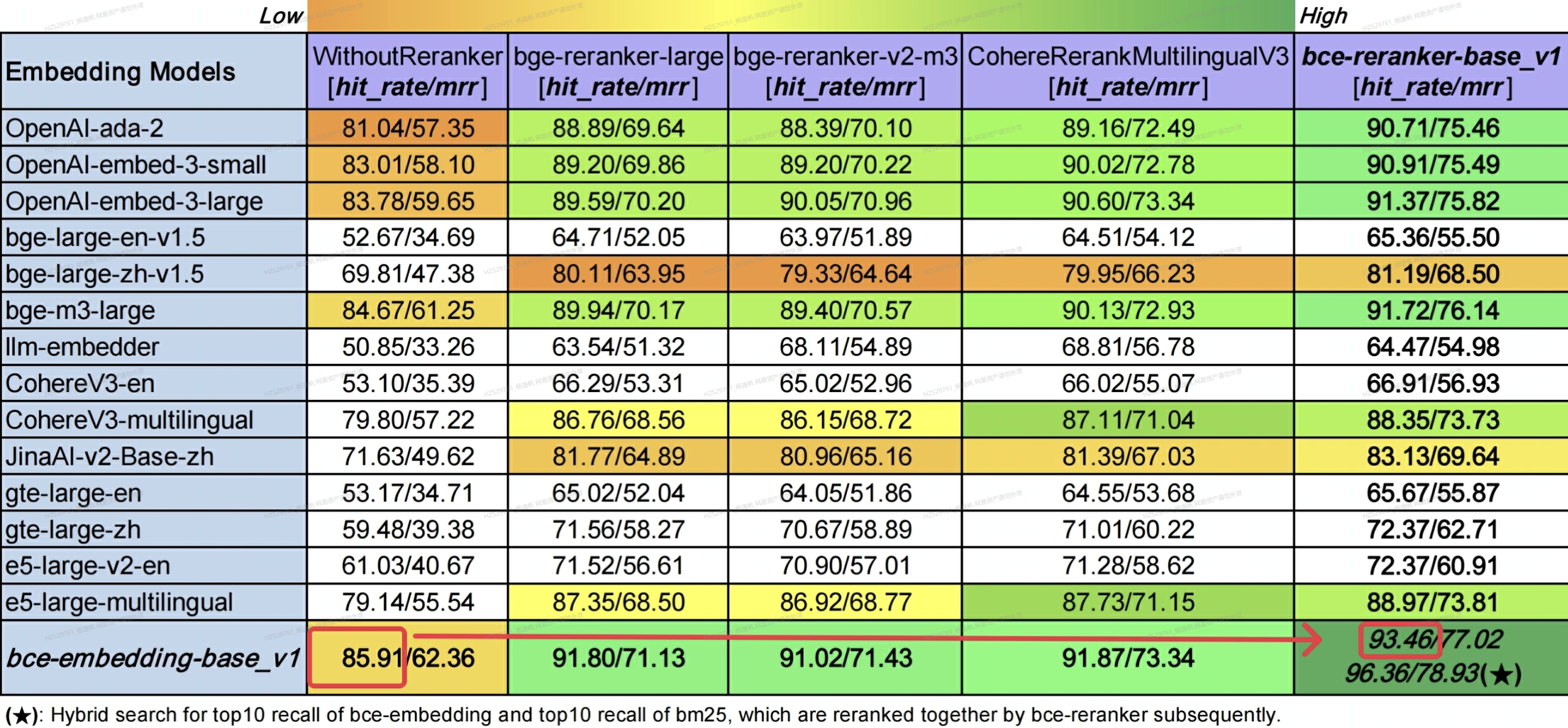
以下是有道 给出的BCE最佳实践
最佳实践(Best practice) :embedding召回top50-100片段,reranker对这50-100片段精排,最后取top5-10片段。
BAAI(北京智源人工智能研究院)也给出了BGE的最佳实践:
For multilingual, utilize BAAI/bge-reranker-v2-m3 and BAAI/bge-reranker-v2-gemma
For Chinese or English, utilize BAAI/bge-reranker-v2-m3 and BAAI/bge-reranker-v2-minicpm-layerwise.
For efficiency, utilize BAAI/bge-reranker-v2-m3 and the low layer of BAAI/ge-reranker-v2-minicpm-layerwise.
For better performance, recommand BAAI/bge-reranker-v2-minicpm-layerwise and BAAI/bge-reranker-v2-gemma
其实我们很容易联想两阶段召回, 其实就是早期的类 DSSM 双塔召回的不同思路。
第一阶段,就是取双塔的最后一层向量做 近邻检索
第二阶段,就是双塔放入query和doc计算的最后的打分
如果想要在自己领域内有更好的效果,也可以选择在领域数据集上微调模型。微调数据如下所示,正样本和负样本,并通过一些hard negative 的方式做样本增强。 现在也有一些思路是用LLM 来对原样本进行一些改写增强,比如给问题换个说法,比如“什么是深度学习?” -> “怎么理解深度学习?”, 这样都能提高原模型在特定领域的效果。
1 | {"query": "如何提高机器学习模型的准确性?", "pos": ["通过交叉验证和调参可以提高模型准确性。"], "neg": ["机器学习是人工智能的一个分支。"]} |
3.3 大模型生成服务
这一步,主要是利用大模型的分析和总结能力,对检索到的相关文档和用户query进行分析,给出用户想要的结果。这里的核心问题也包括几块,1、大模型的选择。 2、prompt调优 3、服务部署以及前端展示 4. inference加速
3.3.1 大模型选择
市面上的开源大模型非常多,其中比较流行的有meta的 llama系列,最新是llama3, 以及Mistral(large不开源) ,google的Gemma(large不开源), 国内的 智普的chatglm,最新是chatglm4, 阿里的qwen,最新是qwen2, 以及baichuan等等非常多。那么这么多开源大模型,如何挑选适合我们的大模型:
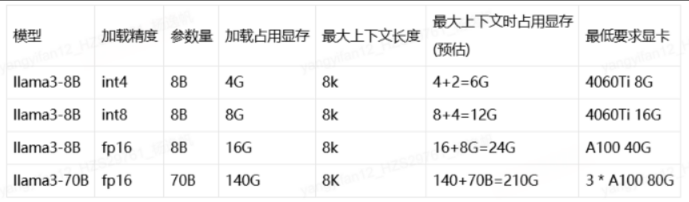
- 模型参数量,适配显存。第一维度需要考虑的就是机器的GPU显存,以下表格,以llama为列子一些常见的模型显存占用,显存占用主要分为2块,
- 一块是加载模型参数占用的显存,在fp16精度下,1B约等于2G显存,可以按这个换算;
- 另一块是生成时,计算的临时变量,以及kvcache占用的显存。在fp16精度下, 1K长度约等于1G, 两者加起来才是跑大模型时的最大显存占用。
- 模型效果。可以参考一些大模型评测网站,比如:https://www.datalearner.com/ai-models/leaderboard/datalearner-llm-leaderboard, 选排在前面的基本没错。不过也需要针对自己的任务多试一些对比。
- 任务适配度。不同的模型训练的领域是不太一样的,比如说,有的在数学相关数据集上训练的多,那么它可能在数学,推理方面效果很好,有些模型是为了做coding的, 有些是做图文的,选择的模型需要适配你自己的任务。如果只是想要简单聊天,那综合性能好的即可。对于这个专门的阅读文档总结用户问题,并需要遵循一定指令的任务,最好选用指令微调的模型

- 社区成熟度。开源模型的一个重要力量,成熟社区模型能让各个框架迅速支持,可用的轮子很多,这也是我们选用的一个重要参考。
基于以上选择思路,我们选择了LLAMA3-8B-instruct 作为大模型来应用,LLAMA3主要是在英文语料上训练的,要想在中文上有比较好的效果,可以继续预训练,网上也已经有很多预训练好的中文LLAMA3, 我们选取的是hfl/llama-3-chinese-8b-instruct-v3
3.3.2 prompt调优
选定大模型之后,就是如何使用的问题了,大模型的角色,包含[‘system’, ‘user’, ‘assistant’]
system 一般代表整个大模型服务。指导模型如何输出,prompt一般放在这里
user 指代的是用户的输入,包括文本,语音,视频等等的输入数据
assistant 代表大模型的相应输出
在我们这个任务中,我们希望大模型根据 我们提供的数据,来对网页内容进行分析,所以我们的prompt
1 | 您是一位专业的研究员和作家,负责回答任何问题。 |
- 设定角色: 开始给模型设定好角色, 研究员和作家
- 指示: 无二义性的任务描述,基于搜索结果总结一个用户问题答案,非口语化,500字,不重复,没结果时也不能乱说
- 上下文:使用明确的xml格式定义好输入的搜索结果
可以多给LLM一些例子看返回结果,根据返回结果对prompt做一定调整。
3.3.3 服务部署以及前端展示
选定模型之后要部署相应的后端模型服务和前端用户交互服务。
后端:
提供模型对话服务给前端进行交互,这里最经典就是openai的 api接口sdk, 为了整个系统的兼容性,我们可以将我们的服务端部署成OPENAI API接口的形式
我们选取的是python目前比较流行的FastAPI, FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架
实现接口主要包括两个,1个是LLM对话服务(v1/chat/completions), 1个是query的embedding服务(v1/embeddings)
1 | @app.post("/v1/chat/completions", response_model=ChatCompletionResponse) |
1 | @app.post("/v1/embeddings", response_model=EmbeddingResponse) |
如果你的机器性能有限,可以选用ollama这个框架来很快速的部署大模型api服务, 官网:https://ollama.com/, 这个平台提供了很多量化的模型和 一行命令部署API服务
1 | # 安装 |
api 客户端调用:
1 | from openai import OpenAI |
前端:
前端采用streamlit前端框架,也是一款易上手的大模型服务前端搭建框架。 以下是个简易的调用大模型聊天的demo服务。非常简单,也就几行代码。
1 | pip installl streamlit # 1.安装包 |
1 | # demo.py |
demo效果:
另外还有一个点就是LLM调用重要的参数如何去选择(top_p, temprature, presence_penalty),我这边整理了几个核心参数的调整思路。 对应我们的这个分析任务,显然是以新闻资料为核心,寻求生成的确定性。

3.3.4 inference加速
大模型虽然效果优越,但是也因为它”大“,导致服务性能很低,在我们部署服务时,需要采取一定的策略对模型预测进行加速才能获得更好的体验。
经过调研选择了VLLM这个大模型推理加速框架。 它有几个优点:
1.社区活跃,模型支持很快
2.加速效果明显。基于虚拟内存和分页的思想, 采用page attention ,允许在非连续的内存空间内存储token,内存的利用率接近于最优
3.使用简单,两行命令即可部署。 示例如下
1 | # vllm llama3 openai |
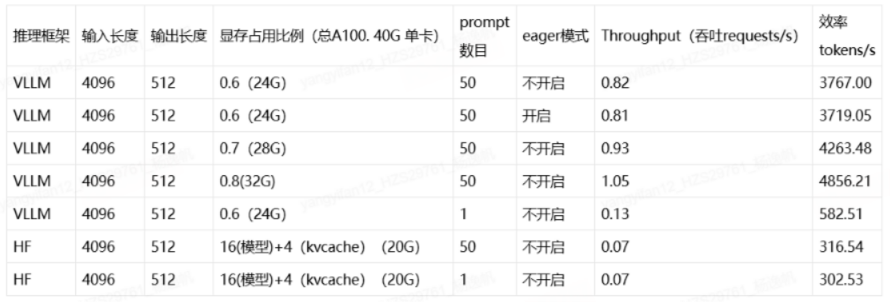
为了测试实际环境下的效果,我们运行了vllm的对比测试脚本
1 | git clone https://github.com/vllm-project/vllm.git |
效果如下所示,可以看到单条inference 性能上,VLLM大约是HF的两倍, 但是当并发时,VLLM效果提升明显,吞吐量提升10倍。
当然,我们可以根据我们的显卡环境采取其他的加速方法,如
- 输入输出优化。 如prompt 裁剪, 规整; 限制输出序列长度等
- 模型优化。 模型压缩, 使用量化模型,使用更小参数模型等等
下面来看看整体效果的演示, 速度还是非常快的:
4. 总结
RAG的agent开发,入门还是比较简单的,现在市面上可用的框架也非常多,只需花费一些时间就能搭出一个可用的demo. 但是想要做的好,稳定服务,还是需要费很多的功夫去研究的,希望我的经验能给大家带来一些收获,少走一些弯路。
目前这个系统还不是很完善, 包括相关性判断,搜索意图判断等都有很大的优化空间。做这个东西的初衷是希望能在音乐热点的场景中进行应用,目前也已经在实践的过程中了,去辅助音乐热点的挖掘和运营。后续的话还希望添加的功能包括:
- 音乐热点的识别与事件总结。
- 结合云音乐站内知识做融合,分析。比如识别事件歌手,歌曲,原因,产出文案等等。
参考文献:
[1]. Azure AI Search: Outperforming vector search with hybrid retrieval and ranking capabilities
[3]. RAG 高效应用指南:Embedding 模型的选择和微调
[4]. ReRank 与 Embedding 模型的区别? 如何选择 ReRank 模型?
[5]. 【时代前沿】:单测场景下tempature、top_p、frequency_penalty、presence_penalty参数调整经验分享