java-多线程-ThreadLocal和线程池
ThreadLocal
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。如果想实现每一个线程都有自己的专属本地变量该如何解决呢?
JDK 中自带的ThreadLocal类正是为了解决这样的问题。 ThreadLocal类主要解决的就是让每个线程绑定自己的值,可以将ThreadLocal类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。
如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是ThreadLocal变量名的由来。他们可以使用 get() 和 set() 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。
再举个简单的例子:两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
数据结构
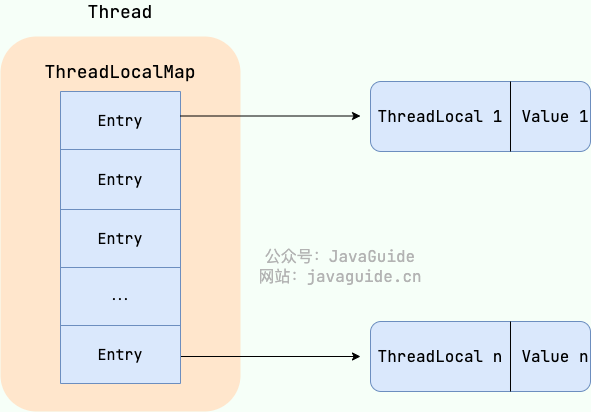
其实不是ThreadLocal有这个数据结构,是Thread持有的,有一个ThreadLocalMap的数组,专门放键值对,K为ThreadLocal的类对象,V为ThreadLocal泛型的数据。
也就是说,在一个线程中,如果有多个ThreadLocal,查找Map键为这个ThreadLocal变量,就可以很轻松拿到存的值。
1 | public void set(T value) { |
内存泄露问题
这个Map里面,Key是弱引用的,也就是说每次gc都会回收key,而value是强引用的。这个时候就会出现,key被gc回收了为null,value还有的情况。这个时候就会产生内存泄露。
解决方法:释放的时候手动remove。
线程池的四个种类
- newCachedThreadPool创建一个可缓存的线程池,默认阻塞队列是SynchronousQueue
- newFixedThreadPool创建一个定长的线程池,默认阻塞队列是LinkedBlockingQueue
- newSingleThreadExecutor创建一个单例线程,默认也是LinkedBlockingQueue
- newScheduled创建一个可以设置定时任务的线程
线程池的核心参数
除了上面四种封装好的,还可以自己创建
1 | /** |
七个核心参数:
- 核心线程数量
- 最大线程数量
- 过期时间:如果线程池的线程数量大于核心线程数量,如果没有新的任务提交,那么已经到期的线程不会立刻销毁,而是等一段时间销毁
- 过期时间单位:可以是秒,毫秒
- 阻塞队列:刚刚提的那些,后面还会说
- 饱和缩略
- 线程工厂类:一般都是默认的,可以定制线程对象的创建,例如设置线程名字、是否是守护线程等
饱和策略
当阻塞队列满了,而且最大线程数量也满了,就会触发饱和策略
- 抛出异常,不让加了
- 线程不走线程池,提交线程的那个线程自己来运行
- 不报错,直接丢弃
- 丢弃队列最前面那个,然后加进队列
如何确定线程数量
- io密集型:2n+1
- cpu密集型:n+1
这里的n都是当前机器的虚拟内核数量,io密集型主要都是io时间多,对于cpu负载并不大