redis-缓存三兄弟
缓存穿透
这里的redis可以全部想象成cache,数据库可以想象成cpu,穿透有点绕过redis的意思
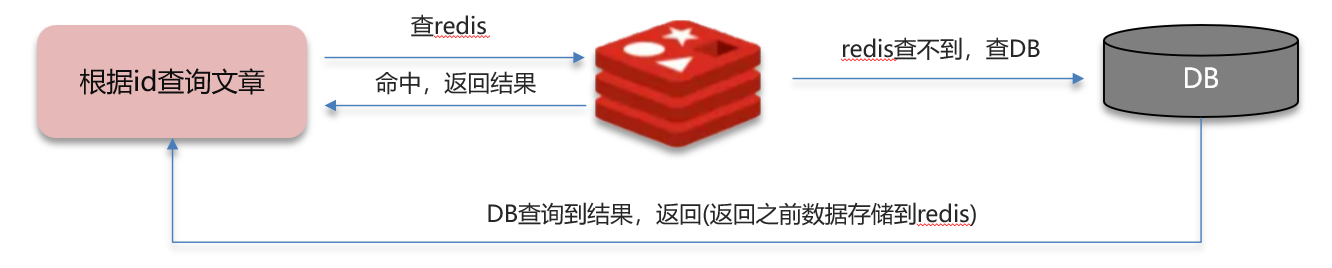
假设有一个请求api/news/getById/1,但是这个id为1的键并不存在于数据库,所以也不会存在于缓存,那么如果有很多这种请求,那么都会绕过redis去查询数据库,造成数据库的负载。
解决方法
- 缓存空数据,就算是数据库找不到也要缓存一个空数据给redis,要不然就会一直会去绕过redis去找数据库。比如给的key=1但是mysql没有相应数据,那么在redis上缓存一个key=1,value=null的键值对。
- 优点:非常简单,维护方便
- 缺点:会造成额外的内存消耗,因为redis是存在内存中的,有多少个没有的键就会有多少个空,浪费内存。还可能造成短期不一致问题,如果在redis里面存了这个空但是这个时候数据库更新了这个键值对,那么在这一段时间访问redis的还是null,就会造成不一致的问题
- 布隆过滤器
在客户端与Redis之间加了一个布隆过滤器,对于请求进行过滤。

布隆过滤器
- bitmap(位图):bit位的数组,数组的元素是0或者1,所以布隆过滤器占用的内存小
- 作用:可以用来检索元素,相当于一种校验电路
- 实现原理:类似hashmap,假设来了一个键,用三种不同的hash算法得到位图的三个位置,然后这些位置都置为1,这里要跟redis缓存的保持一致,在初始化的时候就要预热进布隆过滤器。那么就会有很多重复的,数组越大这种情况会越少。那么此时有一个确实不存在的元素,但是计算出来的三个哈希值就是都是1,那么还是会发生缓存穿透的现象
- 判断不存在的时候一定不存在,也就是说3个地方一定都不为1
- 判断存在的时候不一定存在,因为有可能会有误判
- 优点:内存占用小,没有多余key
- 缺点:实现比较复杂,存在误判,大概在5%左右,但是对于数据库也是可以接受的
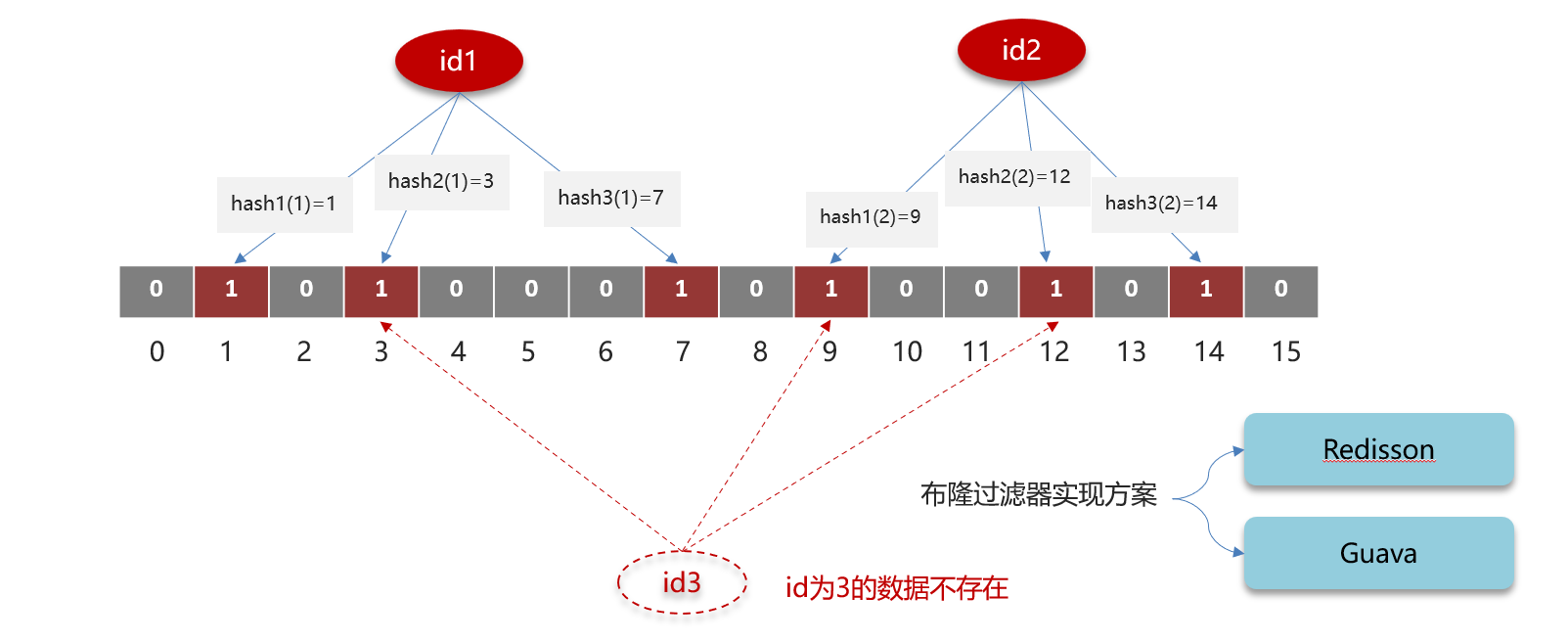
布隆过滤器的大致的原理:布隆过滤器中存放二进制位。数据库的数据通过hash算法计算其hash值并存放到布隆过滤器中,之后判断数据是否存在的时候,就是判断该hash值是0还是1。
但是这个玩意是一种概率上的统计,当其判断不存在的时候就一定是不存在;当其判断存在的时候就不一定存在。所以有一定的穿透风险!!!
缓存击穿
缓存击穿,指的是一个key在不断地支撑高并发,高并发持续对这个点进行访问,当这个点在失效的瞬间,50ms左右,大量的高并发就冲坡缓存请求数据库,造成数据库瘫痪。
对于一般的网站而言很难有缓存击穿的级别,一般是热门网站或者秒杀瞬时高并发。
解决方法
- 互斥锁
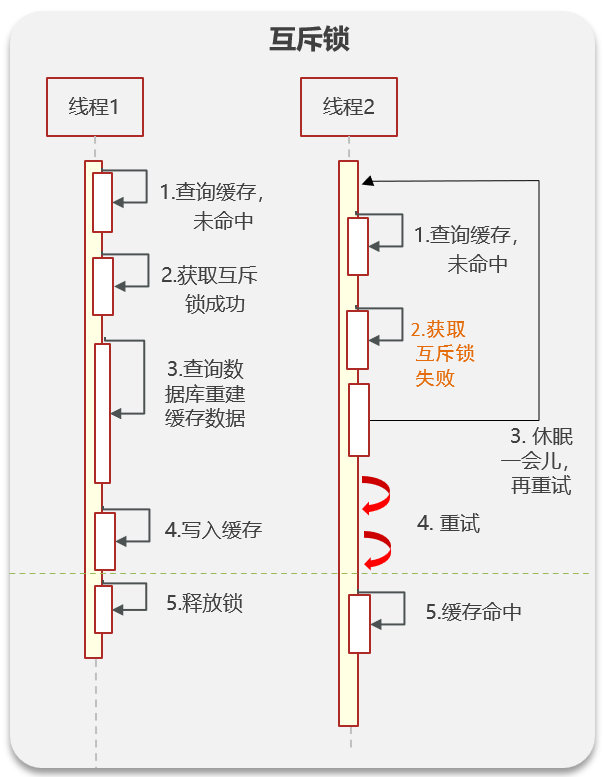
类似pv操作,给临界区上互斥锁,一段时间只要一个线程在重建数据就行,但是这样会造成其他线程等待。通常是需要强一致性的应用需要这种策略。
- 优点:强一致性,在redis没有更新完之前都不许访问,只能要最新的,一般涉及钱的都会有这种逻辑
- 缺点:性能差
- 逻辑过期
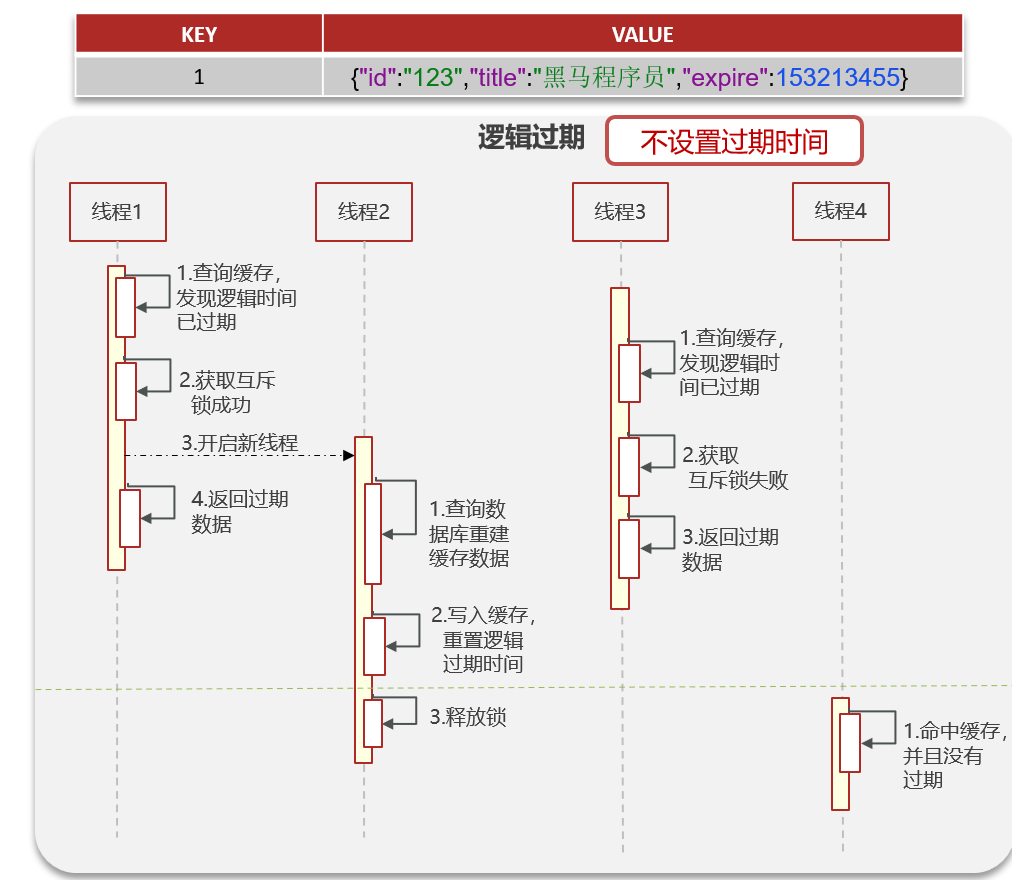
逻辑过期就是在一个键值对的最后加上逻辑时间,并不真实设置过期时间。也就是说,不会真正的过期只会逻辑上的过期。
当一个线程去访问一个逻辑时间到了的键值对,那么其实redis也还有这部分,他还是那这部分旧的数据,但是会开启一个新的线程来完成数据库到mysql的更新
- 优点:可用性强,性能强在不注重强一致性的场景,不会有其他线程等待的情况,但是拿的都是旧数据
- 缺点:一致性弱
缓存雪崩
如果缓存集中在一段时间内过期,那么会有大量的缓存穿透,所有的查询都落在数据库上,造成缓存雪崩
缓存雪崩和缓存击穿的区别:缓存击穿是针对某一个key,缓存雪崩是针对很多key集中过期,
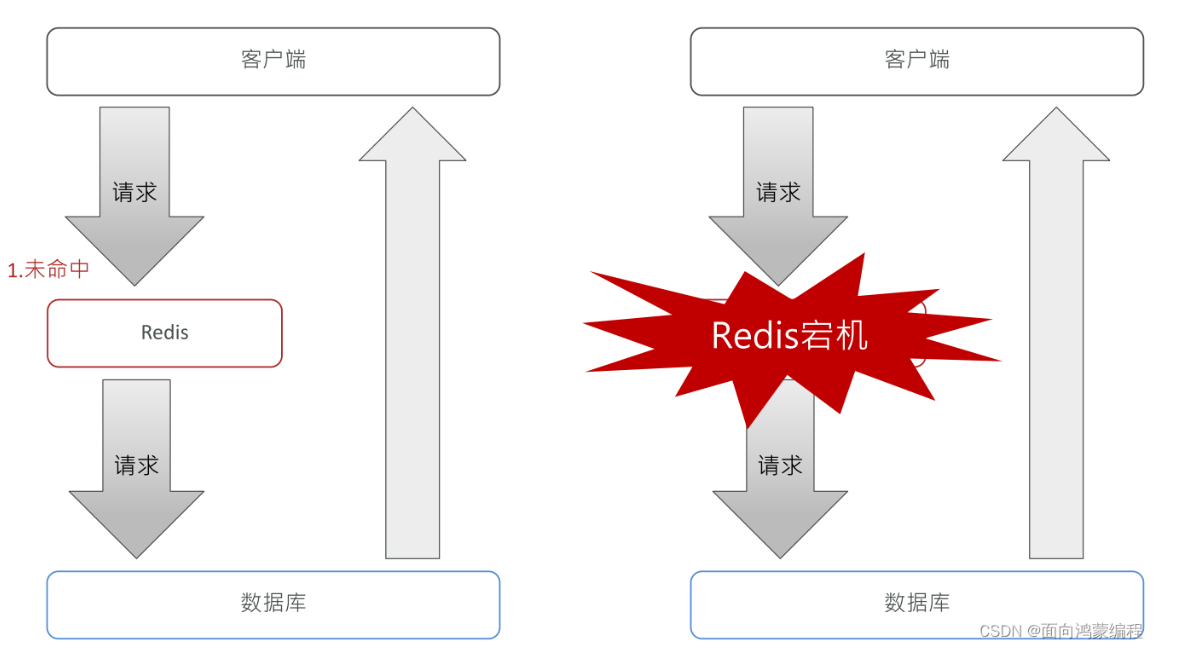
解决方法:
- 给不同的key的TTL添加随机值
- 多个redis集群提高服务的可用性